|
![]()
| Supervised learning Category1 #291948 Supervised learning is the machine learning task of inferring a function from labeled training data.[1] The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. | Supervised learning is the machine learning task of inferring a function from labeled training data.[1] The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. An optimal scenario will allow for the algorithm to correctly determine the class labels for unseen instances. This requires the learning algorithm to generalize from the training data to unseen situations in a "reasonable" way (see inductive bias). The parallel task in human and animal psychology is often referred to as concept learning. Contents [hide] - 1 Overview
- 1.1 Bias-variance tradeoff
- 1.2 Function complexity and amount of training data
- 1.3 Dimensionality of the input space
- 1.4 Noise in the output values
- 1.5 Other factors to consider
- 2 How supervised learning algorithms work
- 2.1 Empirical risk minimization
- 2.2 Structural risk minimization
- 3 Generative training
- 4 Generalizations of supervised learning
- 5 Approaches and algorithms
- 6 Applications
- 7 General issues
- 8 References
- 9 External links
Overview[edit]In order to solve a given problem of supervised learning, one has to perform the following steps: - Determine the type of training examples. Before doing anything else, the user should decide what kind of data is to be used as a training set. In the case of handwriting analysis, for example, this might be a single handwritten character, an entire handwritten word, or an entire line of handwriting.
- Gather a training set. The training set needs to be representative of the real-world use of the function. Thus, a set of input objects is gathered and corresponding outputs are also gathered, either from human experts or from measurements.
- Determine the input feature representation of the learned function. The accuracy of the learned function depends strongly on how the input object is represented. Typically, the input object is transformed into a feature vector, which contains a number of features that are descriptive of the object. The number of features should not be too large, because of the curse of dimensionality; but should contain enough information to accurately predict the output.
- Determine the structure of the learned function and corresponding learning algorithm. For example, the engineer may choose to use support vector machines or decision trees.
- Complete the design. Run the learning algorithm on the gathered training set. Some supervised learning algorithms require the user to determine certain control parameters. These parameters may be adjusted by optimizing performance on a subset (called a validation set) of the training set, or via cross-validation.
- Evaluate the accuracy of the learned function. After parameter adjustment and learning, the performance of the resulting function should be measured on a test set that is separate from the training set.
A wide range of supervised learning algorithms is available, each with its strengths and weaknesses. There is no single learning algorithm that works best on all supervised learning problems (see the No free lunch theorem). There are four major issues to consider in supervised learning: Bias-variance tradeoff[edit]A first issue is the tradeoff between bias and variance.[2] Imagine that we have available several different, but equally good, training data sets. A learning algorithm is biased for a particular input  if, when trained on each of these data sets, it is systematically incorrect when predicting the correct output for . A learning algorithm has high variance for a particular input if it predicts different output values when trained on different training sets. The prediction error of a learned classifier is related to the sum of the bias and the variance of the learning algorithm.[3] Generally, there is a tradeoff between bias and variance. A learning algorithm with low bias must be "flexible" so that it can fit the data well. But if the learning algorithm is too flexible, it will fit each training data set differently, and hence have high variance. A key aspect of many supervised learning methods is that they are able to adjust this tradeoff between bias and variance (either automatically or by providing a bias/variance parameter that the user can adjust). if, when trained on each of these data sets, it is systematically incorrect when predicting the correct output for . A learning algorithm has high variance for a particular input if it predicts different output values when trained on different training sets. The prediction error of a learned classifier is related to the sum of the bias and the variance of the learning algorithm.[3] Generally, there is a tradeoff between bias and variance. A learning algorithm with low bias must be "flexible" so that it can fit the data well. But if the learning algorithm is too flexible, it will fit each training data set differently, and hence have high variance. A key aspect of many supervised learning methods is that they are able to adjust this tradeoff between bias and variance (either automatically or by providing a bias/variance parameter that the user can adjust). Function complexity and amount of training data[edit]The second issue is the amount of training data available relative to the complexity of the "true" function (classifier or regression function). If the true function is simple, then an "inflexible" learning algorithm with high bias and low variance will be able to learn it from a small amount of data. But if the true function is highly complex (e.g., because it involves complex interactions among many different input features and behaves differently in different parts of the input space), then the function will only be learnable from a very large amount of training data and using a "flexible" learning algorithm with low bias and high variance. Good learning algorithms therefore automatically adjust the bias/variance tradeoff based on the amount of data available and the apparent complexity of the function to be learned. Dimensionality of the input space[edit]A third issue is the dimensionality of the input space. If the input feature vectors have very high dimension, the learning problem can be difficult even if the true function only depends on a small number of those features. This is because the many "extra" dimensions can confuse the learning algorithm and cause it to have high variance. Hence, high input dimensionality typically requires tuning the classifier to have low variance and high bias. In practice, if the engineer can manually remove irrelevant features from the input data, this is likely to improve the accuracy of the learned function. In addition, there are many algorithms for feature selection that seek to identify the relevant features and discard the irrelevant ones. This is an instance of the more general strategy of dimensionality reduction, which seeks to map the input data into a lower dimensional space prior to running the supervised learning algorithm. Noise in the output values[edit]A fourth issue is the degree of noise in the desired output values (the supervisory targets). If the desired output values are often incorrect (because of human error or sensor errors), then the learning algorithm should not attempt to find a function that exactly matches the training examples. Attempting to fit the data too carefully leads to overfitting. You can overfit even when there are no measurement errors (stochastic noise) if the function you are trying to learn is too complex for your learning model. In such a situation that part of the target function that cannot be modeled "corrupts" your training data - this phenomenon has been called deterministic noise. When either type of noise is present, it is better to go with a higher bias, lower variance estimator. In practice, there are several approaches to alleviate noise in the output values such as early stopping to prevent overfitting as well as detecting and removing the noisy training examples prior to training the supervised learning algorithm. There are several algorithms that identify noisy training examples and removing the suspected noisy training examples prior to training has decreased generalization error with statistical significance.[4][5] Other factors to consider[edit]Other factors to consider when choosing and applying a learning algorithm include the following: - Heterogeneity of the data. If the feature vectors include features of many different kinds (discrete, discrete ordered, counts, continuous values), some algorithms are easier to apply than others. Many algorithms, including Support Vector Machines, linear regression, logistic regression, neural networks, and nearest neighbor methods, require that the input features be numerical and scaled to similar ranges (e.g., to the [-1,1] interval). Methods that employ a distance function, such as nearest neighbor methods and support vector machines with Gaussian kernels, are particularly sensitive to this. An advantage of decision trees is that they easily handle heterogeneous data.
- Redundancy in the data. If the input features contain redundant information (e.g., highly correlated features), some learning algorithms (e.g., linear regression, logistic regression, and distance based methods) will perform poorly because of numerical instabilities. These problems can often be solved by imposing some form of regularization.
- Presence of interactions and non-linearities. If each of the features makes an independent contribution to the output, then algorithms based on linear functions (e.g., linear regression, logistic regression, Support Vector Machines,naive Bayes) and distance functions (e.g., nearest neighbor methods, support vector machines with Gaussian kernels) generally perform well. However, if there are complex interactions among features, then algorithms such asdecision trees and neural networks work better, because they are specifically designed to discover these interactions. Linear methods can also be applied, but the engineer must manually specify the interactions when using them.
When considering a new application, the engineer can compare multiple learning algorithms and experimentally determine which one works best on the problem at hand (see cross validation). Tuning the performance of a learning algorithm can be very time-consuming. Given fixed resources, it is often better to spend more time collecting additional training data and more informative features than it is to spend extra time tuning the learning algorithms. The most widely used learning algorithms are Support Vector Machines, linear regression, logistic regression, naive Bayes, linear discriminant analysis, decision trees, k-nearest neighbor algorithm, and Neural Networks (Multilayer perceptron). How supervised learning algorithms work[edit]Given a set of  training examples of the form training examples of the form 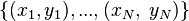 such that such that  is the feature vector of the i-th example and is the feature vector of the i-th example and 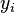 is its label (i.e., class), a learning algorithm seeks a function is its label (i.e., class), a learning algorithm seeks a function 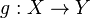 , where , where  is the input space and is the input space and  is the output space. The function is the output space. The function  is an element of some space of possible functions is an element of some space of possible functions  , usually called the hypothesis space. It is sometimes convenient to represent using a scoring function , usually called the hypothesis space. It is sometimes convenient to represent using a scoring function 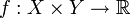 such that is defined as returning the such that is defined as returning the  value that gives the highest score: value that gives the highest score: 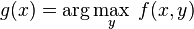 . Let . Let  denote the space of scoring functions. denote the space of scoring functions. Although and can be any space of functions, many learning algorithms are probabilistic models where takes the form of a conditional probability model 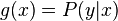 , or , or  takes the form of a joint probability model takes the form of a joint probability model 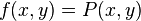 . For example, naive Bayes and linear discriminant analysis are joint probability models, whereas logistic regression is a conditional probability model. . For example, naive Bayes and linear discriminant analysis are joint probability models, whereas logistic regression is a conditional probability model. There are two basic approaches to choosing or : empirical risk minimization and structural risk minimization.[6] Empirical risk minimization seeks the function that best fits the training data. Structural risk minimize includes a penalty function that controls the bias/variance tradeoff. In both cases, it is assumed that the training set consists of a sample of independent and identically distributed pairs, 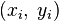 . In order to measure how well a function fits the training data, a loss function . In order to measure how well a function fits the training data, a loss function 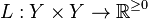 is defined. For training example , the loss of predicting the value is defined. For training example , the loss of predicting the value 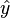 is is  . . The risk  of function is defined as the expected loss of . This can be estimated from the training data as of function is defined as the expected loss of . This can be estimated from the training data as  . . Empirical risk minimization[edit]In empirical risk minimization, the supervised learning algorithm seeks the function that minimizes . Hence, a supervised learning algorithm can be constructed by applying an optimization algorithm to find . When is a conditional probability distribution 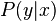 and the loss function is the negative log likelihood: and the loss function is the negative log likelihood: 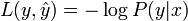 , then empirical risk minimization is equivalent to maximum likelihood estimation. , then empirical risk minimization is equivalent to maximum likelihood estimation. When contains many candidate functions or the training set is not sufficiently large, empirical risk minimization leads to high variance and poor generalization. The learning algorithm is able to memorize the training examples without generalizing well. This is called overfitting. Structural risk minimization[edit]Structural risk minimization seeks to prevent overfitting by incorporating a regularization penalty into the optimization. The regularization penalty can be viewed as implementing a form of Occam's razor that prefers simpler functions over more complex ones. A wide variety of penalties have been employed that correspond to different definitions of complexity. For example, consider the case where the function is a linear function of the form  . . A popular regularization penalty is 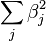 , which is the squared Euclidean norm of the weights, also known as the , which is the squared Euclidean norm of the weights, also known as the 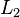 norm. Other norms include the norm. Other norms include the  norm, norm,  , and the , and the 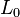 norm, which is the number of non-zero norm, which is the number of non-zero  s. The penalty will be denoted by s. The penalty will be denoted by 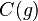 . . The supervised learning optimization problem is to find the function that minimizes 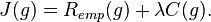 The parameter  controls the bias-variance tradeoff. When controls the bias-variance tradeoff. When 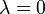 , this gives empirical risk minimization with low bias and high variance. When is large, the learning algorithm will have high bias and low variance. The value of can be chosen empirically via cross validation. , this gives empirical risk minimization with low bias and high variance. When is large, the learning algorithm will have high bias and low variance. The value of can be chosen empirically via cross validation. The complexity penalty has a Bayesian interpretation as the negative log prior probability of , 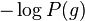 , in which case , in which case 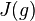 is the posterior probabability of . is the posterior probabability of . Generative training[edit]The training methods described above are discriminative training methods, because they seek to find a function that discriminates well between the different output values (see discriminative model). For the special case where is a joint probability distribution and the loss function is the negative log likelihood  a risk minimization algorithm is said to perform generative training, because can be regarded as agenerative model that explains how the data were generated. Generative training algorithms are often simpler and more computationally efficient than discriminative training algorithms. In some cases, the solution can be computed in closed form as in naive Bayes and linear discriminant analysis. a risk minimization algorithm is said to perform generative training, because can be regarded as agenerative model that explains how the data were generated. Generative training algorithms are often simpler and more computationally efficient than discriminative training algorithms. In some cases, the solution can be computed in closed form as in naive Bayes and linear discriminant analysis. Generalizations of supervised learning[edit]There are several ways in which the standard supervised learning problem can be generalized: - Semi-supervised learning: In this setting, the desired output values are provided only for a subset of the training data. The remaining data is unlabeled.
- Active learning: Instead of assuming that all of the training examples are given at the start, active learning algorithms interactively collect new examples, typically by making queries to a human user. Often, the queries are based on unlabeled data, which is a scenario that combines semi-supervised learning with active learning.
- Structured prediction: When the desired output value is a complex object, such as a parse tree or a labeled graph, then standard methods must be extended.
- Learning to rank: When the input is a set of objects and the desired output is a ranking of those objects, then again the standard methods must be extended.
Approaches and algorithms[edit]Applications[edit]General issues[edit]References[edit] - Jump up^ Mehryar Mohri, Afshin Rostamizadeh, Ameet Talwalkar (2012) Foundations of Machine Learning, The MIT Press ISBN 9780262018258.
- Jump up^ S. Geman, E. Bienenstock, and R. Doursat (1992). Neural networks and the bias/variance dilemma. Neural Computation 4, 1–58.
- Jump up^ G. James (2003) Variance and Bias for General Loss Functions, Machine Learning 51, 115-135. (http://www-bcf.usc.edu/~gareth/research/bv.pdf)
- Jump up^ C.E. Brodely and M.A. Friedl (1999). Identifying and Eliminating Mislabeled Training Instances, Journal of Artificial Intelligence Research 11, 131-167. (http://jair.org/media/606/live-606-1803-jair.pdf)
- Jump up^ M.R. Smith and T. Martinez (2011). "Improving Classification Accuracy by Identifying and Removing Instances that Should Be Misclassified". Proceedings of International Joint Conference on Neural Networks (IJCNN 2011). pp. 2690–2697.
- Jump up^ Vapnik, V. N. The Nature of Statistical Learning Theory (2nd Ed.), Springer Verlag, 2000.
External links[edit] - mloss.org: a directory of open source machine learning software.
|
+Citations (1) - CitationsAdd new citationList by: CiterankMapLink[1] Wikipedia
Author: Various
Cited by: Roger Yau 2:36 PM 21 October 2013 GMT
Citerank: (28) 291862AODE - Averaged one-dependence estimatorsAveraged one-dependence estimators (AODE) is a probabilistic classification learning technique. It was developed to address the attribute-independence problem of the popular naive Bayes classifier. It frequently develops substantially more accurate classifiers than naive Bayes at the cost of a modest increase in the amount of computation.109FDEF6, 291863Artificial neural networkIn computer science and related fields, artificial neural networks are computational models inspired by animal central nervous systems (in particular the brain) that are capable of machine learning and pattern recognition. They are usually presented as systems of interconnected "neurons" that can compute values from inputs by feeding information through the network.109FDEF6, 291936BackpropagationBackpropagation, an abbreviation for "backward propagation of errors", is a common method of training artificial neural networks. From a desired output, the network learns from many inputs, similar to the way a child learns to identify a dog from examples of dogs.109FDEF6, 291937Bayesian statisticsBayesian statistics is a subset of the field of statistics in which the evidence about the true state of the world is expressed in terms of degrees of belief or, more specifically, Bayesian probabilities. Such an interpretation is only one of a number of interpretations of probability and there are other statistical techniques that are not based on "degrees of belief".109FDEF6, 291938Naive Bayes classifierA naive Bayes classifier is a simple probabilistic classifier based on applying Bayes' theorem with strong (naive) independence assumptions. A more descriptive term for the underlying probability model would be "independent feature model". An overview of statistical classifiers is given in the article on Pattern recognition.109FDEF6, 291939Bayesian networkA Bayesian network, Bayes network, belief network, Bayes(ian) model or probabilistic directed acyclic graphical model is a probabilistic graphical model (a type of statistical model) that represents a set of random variables and their conditional dependencies via a directed acyclic graph (DAG). For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. 109FDEF6, 291941Case-based reasoningCase-based reasoning (CBR), broadly construed, is the process of solving new problems based on the solutions of similar past problems. An auto mechanic who fixes an engine by recalling another car that exhibited similar symptoms is using case-based reasoning. So, too, an engineer copying working elements of nature (practicing biomimicry), is treating nature as a database of solutions to problems. Case-based reasoning is a prominent kind of analogy making.109FDEF6, 291942Decision tree learningDecision tree learning uses a decision tree as a predictive model which maps observations about an item to conclusions about the item's target value. It is one of the predictive modelling approaches used in statistics, data mining and machine learning. More descriptive names for such tree models are classification trees or regression trees. In these tree structures, leaves represent class labels and branches represent conjunctions of features that lead to those class labels.109FDEF6, 291943Inductive logic programmingInductive logic programming (ILP) is a subfield of machine learning which uses logic programming as a uniform representation for examples, background knowledge and hypotheses. Given an encoding of the known background knowledge and a set of examples represented as a logical database of facts, an ILP system will derive a hypothesised logic program which entails all the positive and none of the negative examples.109FDEF6, 291944Gaussian process regression (Kriging)Kriging is a method to build an approximation of a function from a set of evaluations of the function at a finite set of points. The method originates from the domain of geostatistics and is now widely used in the domain of spatial analysis and computer experiments. The technique is also known as Gaussian process regression, Kolmogorov Wiener prediction, or Best Linear Unbiased Prediction.109FDEF6, 291945Gene expression programmingGene expression programming (GEP) is an evolutionary algorithm that creates computer programs or models. These computer programs are complex tree structures that learn and adapt by changing their sizes, shapes, and composition, much like a living organism. And like living organisms, the computer programs of GEP are also encoded in simple linear chromosomes of fixed length. Thus, GEP is a genotype-phenotype system.109FDEF6, 291946Group method of data handlingGroup method of data handling (GMDH) is a family of inductive algorithms for computer-based mathematical modeling of multi-parametric datasets that features fully automatic structural and parametric optimization of models.109FDEF6, 291947Learning automataA branch of the theory of adaptive control is devoted to learning automata surveyed by Narendra and Thathachar which were originally described explicitly as finite state automata. Learning automata select their current action based on past experiences from the environment.109FDEF6, 291950Unsupervised learningIn machine learning, the problem of unsupervised learning is that of trying to find hidden structure in unlabeled data. Since the examples given to the learner are unlabeled, there is no error or reward signal to evaluate a potential solution. This distinguishes unsupervised learning from supervised learning and reinforcement learning.25CBCBFF, 291951Reinforcement learningReinforcement learning is an area of machine learning inspired by behaviorist psychology, concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward. The problem, due to its generality, is studied in many other disciplines, such as game theory, control theory, operations research, information theory, simulation-based optimization, statistics, and genetic algorithms.25CBCBFF, 292450Hierarchical clusteringIn data mining, hierarchical clustering is a method of cluster analysis which seeks to build a hierarchy of clusters. Strategies for hierarchical clustering generally fall into two types:
Agglomerative: This is a "bottom up" approach: each observation starts in its own cluster, and pairs of clusters are merged as one moves up the hierarchy.
Divisive: This is a "top down" approach: all observations start in one cluster, and splits are performed recursively as one moves down the hierarch109FDEF6, 292451Association rule learningAssociation rule learning is a popular and well researched method for discovering interesting relations between variables in large databases. It is intended to identify strong rules discovered in databases using different measures of interestingness.109FDEF6, 292454Others25CBCBFF, 292455Learning Vector QuantizationIn computer science, Learning Vector Quantization (LVQ), is a prototype-based supervised classification algorithm. LVQ is the supervised counterpart of vector quantization systems.
LVQ can be understood as a special case of an artificial neural network, more precisely, it applies a winner-take-all Hebbian learning-based approach. It is a precursor to Self-organizing maps (SOM) and related to Neural gas, and to the k-Nearest Neighbor algorithm (k-NN). LVQ was invented by Teuvo Kohonen.109FDEF6, 292463Logistic Model TreeLMT is a classification model with an associated supervised training algorithm that combines logistic regression (LR) and decision tree learning. Logistic model trees are based on the earlier idea of a model tree: a decision tree that has linear regression models at its leaves to provide a piecewise linear regression model (where ordinary decision trees with constants at their leaves would produce a piecewise constant model).109FDEF6, 292464Minimum message lengthMinimum message length (MML) is a formal information theory restatement of Occam's Razor: even when models are not equal in goodness of fit accuracy to the observed data, the one generating the shortest overall message is more likely to be correct (where the message consists of a statement of the model, followed by a statement of data encoded concisely using that model). MML was invented by Chris Wallace, first appearing in the seminal (Wallace and Boulton, 1968).109FDEF6, 292465Lazy learningIn artificial intelligence, lazy learning is a learning method in which generalization beyond the training data is delayed until a query is made to the system, as opposed to in eager learning, where the system tries to generalize the training data before receiving queries.109FDEF6, 292466Instance-based learninginstance-based learning or memory-based learning is a family of learning algorithms that, instead of performing explicit generalization, compare new problem instances with instances seen in training, which have been stored in memory. Instance-based learning is a kind of lazy learning.109FDEF6, 292475k-nearest neighbor algorithmIn pattern recognition, the k-nearest neighbor algorithm (k-NN) is a non-parametric method for classifying objects based on closest training examples in the feature space. k-NN is a type of instance-based learning, or lazy learning where the function is only approximated locally and all computation is deferred until classification. 109FDEF6, 292476Analogical modelingAnalogical modeling (hereafter AM) is a formal theory of exemplar-based analogical reasoning, proposed by Royal Skousen, professor of Linguistics and English language at Brigham Young University in Provo, Utah. It is applicable to language modeling and other categorization tasks. Analogical modeling is related to connectionism and nearest neighbor approaches, in that it is data-based rather than abstraction-based.109FDEF6, 292478Probably approximately correct learningIn this framework, the learner receives samples and must select a generalization function (called the hypothesis) from a certain class of possible functions. The goal is that, with high probability (the "probably" part), the selected function will have low generalization error (the "approximately correct" part). The learner must be able to learn the concept given any arbitrary approximation ratio, probability of success, or distribution of the samples.109FDEF6, 292480Ripple-down rulesRipple Down Rules is a way of approaching knowledge acquisition. Knowledge acquisition refers to the transfer of knowledge from human experts to knowledge based systems.109FDEF6, 292481Support vector machinesIn machine learning, support vector machines (SVMs, also support vector networks[1]) are supervised learning models with associated learning algorithms that analyze data and recognize patterns, used for classification and regression analysis. 109FDEF6 URL: |
|
|