In decision tree learning, ID3 (Iterative Dichotomiser 3) is an algorithm invented by Ross Quinlan[1] used to generate a decision tree from a dataset. ID3 is the precursor to the C4.5 algorithm, and is typically used in the machine learning and natural language processing domains.
Contents
[hide] - 1 Algorithm
- 1.1 Summary
- 1.2 Pseudocode
- 1.3 Properties
- 1.4 Usage
- 2 The ID3 metrics
- 2.1 Entropy
- 2.2 Information Gain
- 3 See also
- 4 References
- 5 External links
Algorithm[edit]
The ID3 algorithm begins with the original set  as the root node. On each iteration of the algorithm, it iterates through every unused attribute of the set and calculates the entropy
as the root node. On each iteration of the algorithm, it iterates through every unused attribute of the set and calculates the entropy 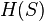 (or information gain
(or information gain 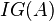 ) of that attribute. Then selects the attribute which has the smallest entropy (or largest information gain) value. The set is then split by the selected attribute (e.g. age < 50, 50 <= age < 100, age >= 100) to produce subsets of the data. The algorithm continues to recurse on each subset, considering only attributes never selected before.
) of that attribute. Then selects the attribute which has the smallest entropy (or largest information gain) value. The set is then split by the selected attribute (e.g. age < 50, 50 <= age < 100, age >= 100) to produce subsets of the data. The algorithm continues to recurse on each subset, considering only attributes never selected before.
Recursion on a subset may stop in one of these cases:
- every element in the subset belongs to the same class (+ or -), then the node is turned into a leaf and labelled with the class of the examples
- there are no more attributes to be selected, but the examples still do not belong to the same class (some are + and some are -), then the node is turned into a leaf and labelled with the most common class of the examples in the subset
- there are no examples in the subset, this happens when no example in the parent set was found to be matching a specific value of the selected attribute, for example if there was no example with age >= 100. Then a leaf is created, and labelled with the most common class of the examples in the parent set.
Throughout the algorithm, the decision tree is constructed with each non-terminal node representing the selected attribute on which the data was split, and terminal nodes representing the class label of the final subset of this branch.
Summary[edit]
- Calculate the entropy of every attribute using the data set
- Split the set into subsets using the attribute for which entropy is minimum (or, equivalently, information gain is maximum)
- Make a decision tree node containing that attribute
- Recurse on subsets using remaining attributes
Pseudocode[edit]
ID3 (Examples, Target_Attribute, Attributes) Create a root node for the tree If all examples are positive, Return the single-node tree Root, with label = +. If all examples are negative, Return the single-node tree Root, with label = -. If number of predicting attributes is empty, then Return the single node tree Root, with label = most common value of the target attribute in the examples. Otherwise Begin A ← The Attribute that best classifies examples. Decision Tree attribute for Root = A. For each possible value,  , of A, Add a new tree branch below Root, corresponding to the test A = . Let Examples() be the subset of examples that have the value for A If Examples() is empty Then below this new branch add a leaf node with label = most common target value in the examples Else below this new branch add the subtree ID3 (Examples(), Target_Attribute, Attributes – {A}) End Return Root
, of A, Add a new tree branch below Root, corresponding to the test A = . Let Examples() be the subset of examples that have the value for A If Examples() is empty Then below this new branch add a leaf node with label = most common target value in the examples Else below this new branch add the subtree ID3 (Examples(), Target_Attribute, Attributes – {A}) End Return Root
Properties[edit]
ID3 does not guarantee an optimal solution, it can get stuck in local optimums. It uses a greedy approach by selecting the best attribute to split the dataset on each iteration. One improvement that can be made on the algorithm can be to use backtrackingduring the search for the optimal decision tree.
ID3 can overfit to the training data, to avoid overfitting, smaller decision trees should be preferred over larger ones. This algorithm usually produces small trees, but it does not always produce the smallest possible tree.
ID3 is harder to use on continuous data. If the values of any given attribute is continuous, then there are many more places to split the data on this attribute, and searching for the best value to split by can be time consuming.
The ID3 algorithm is used by training on a dataset to produce a decision tree which is stored in memory. At runtime, this decision tree is used to classify new unseen test cases by working down the decision tree using the values of this test case to arrive at a terminal node that tells you what class this test case belongs to.
The ID3 metrics[edit]
Entropy[edit]
Entropy is a measure of the amount of uncertainty in the (data) set (i.e. entropy characterizes the (data) set ).
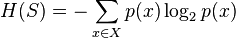
Where,
- - The current (data) set for which entropy is being calculated (changes every iteration of the ID3 algorithm)
 - Set of classes in
- Set of classes in 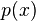 - The proportion of the number of elements in class
- The proportion of the number of elements in class  to the number of elements in set
to the number of elements in set
When 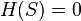 , the set is perfectly classified (i.e. all elements in are of the same class).
, the set is perfectly classified (i.e. all elements in are of the same class).
In ID3, entropy is calculated for each remaining attribute. The attribute with the smallest entropy is used to split the set on this iteration. The higher the entropy, the higher the potential to improve the classification here.
Information Gain[edit]
Information gain is the measure of the difference in entropy from before to after the set is split on an attribute  . In other words, how much uncertainty in was reduced after splitting set on attribute .
. In other words, how much uncertainty in was reduced after splitting set on attribute .
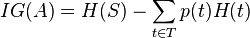
Where,
- - Entropy of set
 - The subsets created from splitting set by attribute such that
- The subsets created from splitting set by attribute such that 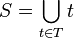
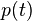 - The proportion of the number of elements in
- The proportion of the number of elements in  to the number of elements in set
to the number of elements in set  - Entropy of subset
- Entropy of subset
In ID3, information gain can be calculated (instead of entropy) for each remaining attribute. The attribute with the largest information gain is used to split the set on this iteration.
See also[edit]
References[edit]
- Jump up^ Quinlan, J. R. 1986. Induction of Decision Trees. Mach. Learn. 1, 1 (Mar. 1986), 81-106
- Mitchell, Tom M. Machine Learning. McGraw-Hill, 1997. pp. 55–58.
- Grzymala-Busse, Jerzy W. "Selected Algorithms of Machine Learning from Examples." Fundamenta Informaticae 18, (1993): 193–207.
External links[edit]