|
![]()
| Artificial neural network Component1 #291863 In computer science and related fields, artificial neural networks are computational models inspired by animal central nervous systems (in particular the brain) that are capable of machine learning and pattern recognition. They are usually presented as systems of interconnected "neurons" that can compute values from inputs by feeding information through the network. | | | | [hide]This article has multiple issues. Please help improve it or discuss these issues on the talk page. | | This article needs additional citations for verification. (March 2009) | | |  An artificial neural network is an interconnected group of nodes, akin to the vast network of neurons in a brain. Here, each circular node represents an artificial neuron and an arrow represents a connection from the output of one neuron to the input of another. In computer science and related fields, artificial neural networks are computational models inspired by animal central nervous systems (in particular the brain) that are capable of machine learning and pattern recognition. They are usually presented as systems of interconnected "neurons" that can compute values from inputs by feeding information through the network. For example, in a neural network for handwriting recognition, a set of input neurons may be activated by the pixels of an input image representing a letter or digit. The activations of these neurons are then passed on, weighted and transformed by some function determined by the network's designer, to other neurons, etc., until finally an output neuron is activated that determines which character was read. Like other machine learning methods, neural networks have been used to solve a wide variety of tasks that are hard to solve using ordinary rule-based programming, including computer vision and speech recognition. Contents [hide] - 1 Background
- 2 History
- 3 Models
- 3.1 Network function
- 3.2 Learning
- 3.2.1 Choosing a cost function
- 3.3 Learning paradigms
- 3.3.1 Supervised learning
- 3.3.2 Unsupervised learning
- 3.3.3 Reinforcement learning
- 3.4 Learning algorithms
- 4 Employing artificial neural networks
- 5 Applications
- 5.1 Real-life applications
- 5.2 Neural networks and neuroscience
- 6 Neural network software
- 7 Types of artificial neural networks
- 8 Theoretical properties
- 8.1 Computational power
- 8.2 Capacity
- 8.3 Convergence
- 8.4 Generalization and statistics
- 8.5 Dynamic properties
- 9 Criticism
- 10 Successes in pattern recognition contests since 2009
- 11 Gallery
- 12 See also
- 13 References
- 14 Bibliography
- 15 External links
Background[edit]The inspiration for neural networks came from examination of central nervous systems. In an artificial neural network, simple artificial nodes, called "neurons", "neurodes", "processing elements" or "units", are connected together to form a network which mimics a biological neural network. There is no single formal definition of what an artificial neural network is. Commonly, though, a class of statistical models will be called "neural" if they - consist of sets of adaptive weights, i.e. numerical parameters that are tuned by a learning algorithm, and
- are capable of approximating non-linear functions of their inputs.
The adaptive weights are conceptually connection strengths between neurons, which are activated during training and prediction. Neural networks are also similar to biological neural networks in performing functions collectively and in parallel by the units, rather than there being a clear delineation of subtasks to which various units are assigned. The term "neural network" usually refers to models employed in statistics, cognitive psychology and artificial intelligence. Neural network models which emulate the central nervous system are part of theoretical neuroscience and computational neuroscience. In modern software implementations of artificial neural networks, the approach inspired by biology has been largely abandoned for a more practical approach based on statistics and signal processing. In some of these systems, neural networks or parts of neural networks (like artificial neurons) form components in larger systems that combine both adaptive and non-adaptive elements. While the more general approach of such systems is more suitable for real-world problem solving, it has far less to do with the traditional artificial intelligence connectionist models. What they do have in common, however, is the principle of non-linear, distributed, parallel and local processing and adaptation. Historically, the use of neural networks models marked a paradigm shift in the late eighties from high-level (symbolic) artificial intelligence, characterized by expert systems with knowledge embodied in if-then rules, to low-level (sub-symbolic) machine learning, characterized by knowledge embodied in the parameters of a dynamical system. History[edit]Warren McCulloch and Walter Pitts[1] (1943) created a computational model for neural networks based on mathematics and algorithms. They called this model threshold logic. The model paved the way for neural network research to split into two distinct approaches. One approach focused on biological processes in the brain and the other focused on the application of neural networks to artificial intelligence. In the late 1940s psychologist Donald Hebb[2] created a hypothesis of learning based on the mechanism of neural plasticity that is now known as Hebbian learning. Hebbian learning is considered to be a 'typical' unsupervised learning rule and its later variants were early models for long term potentiation. These ideas started being applied to computational models in 1948 with Turing's B-type machines. Farley and Clark[3] (1954) first used computational machines, then called calculators, to simulate a Hebbian network at MIT. Other neural network computational machines were created by Rochester, Holland, Habit, and Duda[4] (1956). Frank Rosenblatt[5] (1958) created the perceptron, an algorithm for pattern recognition based on a two-layer learning computer network using simple addition and subtraction. With mathematical notation, Rosenblatt also described circuitry not in the basic perceptron, such as the exclusive-or circuit, a circuit whose mathematical computation could not be processed until after the backpropagation algorithm was created by Paul Werbos[6] (1975). Neural network research stagnated after the publication of machine learning research by Marvin Minsky and Seymour Papert[7] (1969). They discovered two key issues with the computational machines that processed neural networks. The first issue was that single-layer neural networks were incapable of processing the exclusive-or circuit. The second significant issue was that computers were not sophisticated enough to effectively handle the long run time required by large neural networks. Neural network research slowed until computers achieved greater processing power. Also key in later advances was the backpropagation algorithm which effectively solved the exclusive-or problem (Werbos 1975).[6] The parallel distributed processing of the mid-1980s became popular under the name connectionism. The text by David E. Rumelhart and James McClelland[8] (1986) provided a full exposition on the use of connectionism in computers to simulate neural processes. Neural networks, as used in artificial intelligence, have traditionally been viewed as simplified models of neural processing in the brain, even though the relation between this model and brain biological architecture is debated, as it is not clear to what degree artificial neural networks mirror brain function.[9] In the 1990s, neural networks were overtaken in popularity in machine learning by support vector machines and other, much simpler methods such as linear classifiers. Renewed interest in neural nets was sparked in the 2000s by the advent of deep learning. Recent improvements[edit]While initially research had been concerned mostly with the electrical characteristics of neurons, a particularly important part of the investigation in recent years has been the exploration of the role of neuromodulators such as dopamine, acetylcholine, andserotonin on behaviour and learning. Biophysical models, such as BCM theory, have been important in understanding mechanisms for synaptic plasticity, and have had applications in both computer science and neuroscience. Research is ongoing in understanding the computational algorithms used in the brain, with some recent biological evidence for radial basis networks and neural backpropagation as mechanisms for processing data. Computational devices have been created in CMOS for both biophysical simulation and neuromorphic computing. More recent efforts show promise for creating nanodevices[10] for very large scale principal components analyses and convolution. If successful, these efforts could usher in a new era of neural computing[11] that is a step beyond digital computing, because it depends on learning rather than programming and because it is fundamentally analog rather than digital even though the first instantiations may in fact be with CMOS digital devices. Between 2009 and 2012, the recurrent neural networks and deep feedforward neural networks developed in the research group of Jürgen Schmidhuber at the Swiss AI Lab IDSIA have won eight international competitions in pattern recognition and machine learning.[12] For example, multi-dimensional long short term memory (LSTM)[13][14] won three competitions in connected handwriting recognition at the 2009 International Conference on Document Analysis and Recognition (ICDAR), without any prior knowledge about the three different languages to be learned. Variants of the back-propagation algorithm as well as unsupervised methods by Geoff Hinton and colleagues at the University of Toronto[15][16] can be used to train deep, highly nonlinear neural architectures similar to the 1980 Neocognitron by Kunihiko Fukushima,[17] and the "standard architecture of vision",[18] inspired by the simple and complex cells identified by David H. Hubel and Torsten Wiesel in the primary visual cortex. Deep learning feedforward networks alternate convolutional layers and max-pooling layers, topped by several pure classification layers. Fast GPU-based implementations of this approach have won several pattern recognition contests, including the IJCNN 2011 Traffic Sign Recognition Competition[19] and the ISBI 2012 Segmentation of Neuronal Structures in Electron Microscopy Stacks challenge.[20] Such neural networks also were the first artificial pattern recognizers to achieve human-competitive or even superhuman performance[21] on benchmarks such as traffic sign recognition (IJCNN 2012), or the MNIST handwritten digits problem of Yann LeCun and colleagues at NYU. Neural network models in artificial intelligence are usually referred to as artificial neural networks (ANNs); these are essentially simple mathematical models defining a function  or a distribution over or a distribution over  or both and or both and 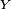 , but sometimes models are also intimately associated with a particular learning algorithm or learning rule. A common use of the phrase ANN model really means the definition of a class of such functions (where members of the class are obtained by varying parameters, connection weights, or specifics of the architecture such as the number of neurons or their connectivity). , but sometimes models are also intimately associated with a particular learning algorithm or learning rule. A common use of the phrase ANN model really means the definition of a class of such functions (where members of the class are obtained by varying parameters, connection weights, or specifics of the architecture such as the number of neurons or their connectivity). Network function[edit]The word network in the term 'artificial neural network' refers to the inter–connections between the neurons in the different layers of each system. An example system has three layers. The first layer has input neurons, which send data via synapses to the second layer of neurons, and then via more synapses to the third layer of output neurons. More complex systems will have more layers of neurons with some having increased layers of input neurons and output neurons. The synapses store parameters called "weights" that manipulate the data in the calculations. An ANN is typically defined by three types of parameters: - The interconnection pattern between different layers of neurons
- The learning process for updating the weights of the interconnections
- The activation function that converts a neuron's weighted input to its output activation.
Mathematically, a neuron's network function 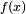 is defined as a composition of other functions is defined as a composition of other functions 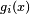 , which can further be defined as a composition of other functions. This can be conveniently represented as a network structure, with arrows depicting the dependencies between variables. A widely used type of composition is the nonlinear weighted sum, where , which can further be defined as a composition of other functions. This can be conveniently represented as a network structure, with arrows depicting the dependencies between variables. A widely used type of composition is the nonlinear weighted sum, where  , where , where 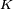 (commonly referred to as the activation function[22]) is some predefined function, such as the hyperbolic tangent. It will be convenient for the following to refer to a collection of functions (commonly referred to as the activation function[22]) is some predefined function, such as the hyperbolic tangent. It will be convenient for the following to refer to a collection of functions  as simply a vector as simply a vector 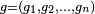 . . This figure depicts such a decomposition of 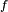 , with dependencies between variables indicated by arrows. These can be interpreted in two ways. , with dependencies between variables indicated by arrows. These can be interpreted in two ways. The first view is the functional view: the input  is transformed into a 3-dimensional vector is transformed into a 3-dimensional vector  , which is then transformed into a 2-dimensional vector , which is then transformed into a 2-dimensional vector  , which is finally transformed into . This view is most commonly encountered in the context of optimization. , which is finally transformed into . This view is most commonly encountered in the context of optimization. The second view is the probabilistic view: the random variable  depends upon the random variable depends upon the random variable 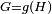 , which depends upon , which depends upon 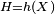 , which depends upon the random variable . This view is most commonly encountered in the context of graphical models. , which depends upon the random variable . This view is most commonly encountered in the context of graphical models. The two views are largely equivalent. In either case, for this particular network architecture, the components of individual layers are independent of each other (e.g., the components of are independent of each other given their input ). This naturally enables a degree of parallelism in the implementation.  Two separate depictions of the recurrent ANN dependency graph Networks such as the previous one are commonly called feedforward, because their graph is a directed acyclic graph. Networks with cycles are commonly called recurrent. Such networks are commonly depicted in the manner shown at the top of the figure, where is shown as being dependent upon itself. However, an implied temporal dependence is not shown. Learning[edit]What has attracted the most interest in neural networks is the possibility of learning. Given a specific task to solve, and a class of functions 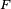 , learning means using a set of observations to find , learning means using a set of observations to find  which solves the task in someoptimal sense. which solves the task in someoptimal sense. This entails defining a cost function  such that, for the optimal solution such that, for the optimal solution  , , 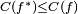  – i.e., no solution has a cost less than the cost of the optimal solution (see Mathematical optimization). – i.e., no solution has a cost less than the cost of the optimal solution (see Mathematical optimization). The cost function 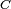 is an important concept in learning, as it is a measure of how far away a particular solution is from an optimal solution to the problem to be solved. Learning algorithms search through the solution space to find a function that has the smallest possible cost. is an important concept in learning, as it is a measure of how far away a particular solution is from an optimal solution to the problem to be solved. Learning algorithms search through the solution space to find a function that has the smallest possible cost. For applications where the solution is dependent on some data, the cost must necessarily be a function of the observations, otherwise we would not be modelling anything related to the data. It is frequently defined as a statistic to which only approximations can be made. As a simple example, consider the problem of finding the model , which minimizes ![\scriptstyle C=E\left[(f(x) - y)^2\right]](http://upload.wikimedia.org/math/d/e/3/de3e13d7da78fefd7905e4acdb26deca.png) , for data pairs , for data pairs 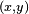 drawn from some distribution drawn from some distribution  . In practical situations we would only have . In practical situations we would only have  samples from and thus, for the above example, we would only minimize samples from and thus, for the above example, we would only minimize  . Thus, the cost is minimized over a sample of the data rather than the entire data set. . Thus, the cost is minimized over a sample of the data rather than the entire data set. When  some form of online machine learning must be used, where the cost is partially minimized as each new example is seen. While online machine learning is often used when is fixed, it is most useful in the case where the distribution changes slowly over time. In neural network methods, some form of online machine learning is frequently used for finite datasets. some form of online machine learning must be used, where the cost is partially minimized as each new example is seen. While online machine learning is often used when is fixed, it is most useful in the case where the distribution changes slowly over time. In neural network methods, some form of online machine learning is frequently used for finite datasets. Choosing a cost function[edit]While it is possible to define some arbitrary, ad hoc cost function, frequently a particular cost will be used, either because it has desirable properties (such as convexity) or because it arises naturally from a particular formulation of the problem (e.g., in a probabilistic formulation the posterior probability of the model can be used as an inverse cost). Ultimately, the cost function will depend on the desired task. An overview of the three (3) main categories of learning tasks is provided below. Learning paradigms[edit]There are three major learning paradigm, each corresponding to a particular abstract learning task. These are supervised learning, unsupervised learning and reinforcement learning. Supervised learning[edit]In supervised learning, we are given a set of example pairs  and the aim is to find a function in the allowed class of functions that matches the examples. In other words, we wish to infer the mapping implied by the data; the cost function is related to the mismatch between our mapping and the data and it implicitly contains prior knowledge about the problem domain. and the aim is to find a function in the allowed class of functions that matches the examples. In other words, we wish to infer the mapping implied by the data; the cost function is related to the mismatch between our mapping and the data and it implicitly contains prior knowledge about the problem domain. A commonly used cost is the mean-squared error, which tries to minimize the average squared error between the network's output, f(x), and the target value y over all the example pairs. When one tries to minimize this cost using gradient descent for the class of neural networks called multilayer perceptrons, one obtains the common and well-known backpropagation algorithm for training neural networks. Tasks that fall within the paradigm of supervised learning are pattern recognition (also known as classification) and regression (also known as function approximation). The supervised learning paradigm is also applicable to sequential data (e.g., for speech and gesture recognition). This can be thought of as learning with a "teacher," in the form of a function that provides continuous feedback on the quality of solutions obtained thus far. Unsupervised learning[edit]In unsupervised learning, some data is given and the cost function to be minimized, that can be any function of the data and the network's output, . The cost function is dependent on the task (what we are trying to model) and our a priori assumptions (the implicit properties of our model, its parameters and the observed variables). As a trivial example, consider the model  , where , where  is a constant and the cost is a constant and the cost ![\scriptstyle C=E[(x - f(x))^2]](http://upload.wikimedia.org/math/7/b/d/7bdfe3a462e428e140cde7d2d15eb817.png) . Minimizing this cost will give us a value of that is equal to the mean of the data. The cost function can be much more complicated. Its form depends on the application: for example, in compression it could be related to the mutual information between and , whereas in statistical modeling, it could be related to the posterior probability of the model given the data. (Note that in both of those examples those quantities would be maximized rather than minimized). . Minimizing this cost will give us a value of that is equal to the mean of the data. The cost function can be much more complicated. Its form depends on the application: for example, in compression it could be related to the mutual information between and , whereas in statistical modeling, it could be related to the posterior probability of the model given the data. (Note that in both of those examples those quantities would be maximized rather than minimized). Tasks that fall within the paradigm of unsupervised learning are in general estimation problems; the applications include clustering, the estimation of statistical distributions, compression and filtering. Reinforcement learning[edit]In reinforcement learning, data are usually not given, but generated by an agent's interactions with the environment. At each point in time  , the agent performs an action , the agent performs an action  and the environment generates an observation and the environment generates an observation  and an instantaneous cost and an instantaneous cost  , according to some (usually unknown) dynamics. The aim is to discover a policy for selecting actions that minimizes some measure of a long-term cost; i.e., the expected cumulative cost. The environment's dynamics and the long-term cost for each policy are usually unknown, but can be estimated. , according to some (usually unknown) dynamics. The aim is to discover a policy for selecting actions that minimizes some measure of a long-term cost; i.e., the expected cumulative cost. The environment's dynamics and the long-term cost for each policy are usually unknown, but can be estimated. More formally, the environment is modeled as a Markov decision process (MDP) with states  and actions and actions  with the following probability distributions: the instantaneous cost distribution with the following probability distributions: the instantaneous cost distribution  , the observation distribution , the observation distribution 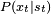 and the transition and the transition  , while a policy is defined as conditional distribution over actions given the observations. Taken together, the two define a Markov chain (MC). The aim is to discover the policy that minimizes the cost; i.e., the MC for which the cost is minimal. , while a policy is defined as conditional distribution over actions given the observations. Taken together, the two define a Markov chain (MC). The aim is to discover the policy that minimizes the cost; i.e., the MC for which the cost is minimal. ANNs are frequently used in reinforcement learning as part of the overall algorithm.[23][24] Dynamic programming has been coupled with ANNs (Neuro dynamic programming) by Bertsekas and Tsitsiklis[25] and applied to multi-dimensional nonlinear problems such as those involved in vehicle routing,[26] natural resources management[27][28] or medicine[29] because of the ability of ANNs to mitigate losses of accuracy even when reducing the discretization grid density for numerically approximating the solution of the original control problems. Tasks that fall within the paradigm of reinforcement learning are control problems, games and other sequential decision making tasks. Learning algorithms[edit]Training a neural network model essentially means selecting one model from the set of allowed models (or, in a Bayesian framework, determining a distribution over the set of allowed models) that minimizes the cost criterion. There are numerous algorithms available for training neural network models; most of them can be viewed as a straightforward application of optimization theory and statistical estimation. Most of the algorithms used in training artificial neural networks employ some form of gradient descent. This is done by simply taking the derivative of the cost function with respect to the network parameters and then changing those parameters in a gradient-related direction. Evolutionary methods,[30] gene expression programming,[31] simulated annealing,[32] expectation-maximization, non-parametric methods and particle swarm optimization[33] are some commonly used methods for training neural networks. Employing artificial neural networks[edit]Perhaps the greatest advantage of ANNs is their ability to be used as an arbitrary function approximation mechanism that 'learns' from observed data. However, using them is not so straightforward, and a relatively good understanding of the underlying theory is essential. - Choice of model: This will depend on the data representation and the application. Overly complex models tend to lead to problems with learning.
- Learning algorithm: There are numerous trade-offs between learning algorithms. Almost any algorithm will work well with the correct hyperparameters for training on a particular fixed data set. However selecting and tuning an algorithm for training on unseen data requires a significant amount of experimentation.
- Robustness: If the model, cost function and learning algorithm are selected appropriately the resulting ANN can be extremely robust.
With the correct implementation, ANNs can be used naturally in online learning and large data set applications. Their simple implementation and the existence of mostly local dependencies exhibited in the structure allows for fast, parallel implementations in hardware. Applications[edit]The utility of artificial neural network models lies in the fact that they can be used to infer a function from observations. This is particularly useful in applications where the complexity of the data or task makes the design of such a function by hand impractical. Real-life applications[edit]The tasks artificial neural networks are applied to tend to fall within the following broad categories: - Function approximation, or regression analysis, including time series prediction, fitness approximation and modeling.
- Classification, including pattern and sequence recognition, novelty detection and sequential decision making.
- Data processing, including filtering, clustering, blind source separation and compression.
- Robotics, including directing manipulators, prosthesis.
- Control, including Computer numerical control
Application areas include system identification and control (vehicle control, process control, natural resources management), quantum chemistry,[34] game-playing and decision making (backgammon, chess, poker), pattern recognition (radar systems, face identification, object recognition and more), sequence recognition (gesture, speech, handwritten text recognition), medical diagnosis, financial applications (automated trading systems), data mining (or knowledge discovery in databases, "KDD"), visualization and e-mail spam filtering. Artificial neural networks have also been used to diagnose several cancers. An ANN based hybrid lung cancer detection system named HLND improves the accuracy of diagnosis and the speed of lung cancer radiology.[35] These networks have also been used to diagnose prostate cancer. The diagnoses can be used to make specific models taken from a large group of patients compared to information of one given patient. The models do not depend on assumptions about correlations of different variables. Colorectal cancer has also been predicted using the neural networks. Neural networks could predict the outcome for a patient with colorectal cancer with more accuracy than the current clinical methods. After training, the networks could predict multiple patient outcomes from unrelated institutions.[36] Neural networks and neuroscience[edit]Theoretical and computational neuroscience is the field concerned with the theoretical analysis and computational modeling of biological neural systems. Since neural systems are intimately related to cognitive processes and behavior, the field is closely related to cognitive and behavioral modeling. The aim of the field is to create models of biological neural systems in order to understand how biological systems work. To gain this understanding, neuroscientists strive to make a link between observed biological processes (data), biologically plausible mechanisms for neural processing and learning (biological neural network models) and theory (statistical learning theory and information theory). Types of models[edit]Many models are used in the field defined at different levels of abstraction and modeling different aspects of neural systems. They range from models of the short-term behavior of individual neurons, models of how the dynamics of neural circuitry arise from interactions between individual neurons and finally to models of how behavior can arise from abstract neural modules that represent complete subsystems. These include models of the long-term, and short-term plasticity, of neural systems and their relations to learning and memory from the individual neuron to the system level. Neural network software[edit]Neural network software is used to simulate, research, develop and apply artificial neural networks, biological neural networks and, in some cases, a wider array of adaptive systems. Types of artificial neural networks[edit]Artificial neural network types vary from those with only one or two layers of single direction logic, to complicated multi–input many directional feedback loops and layers. On the whole, these systems use algorithms in their programming to determine control and organization of their functions. Some may be as simple as a one-neuron layer with an input and an output, and others can mimic complex systems such as dANN, which can mimic chromosomal DNA through sizes at the cellular level, into artificial organisms and simulate reproduction, mutation and population sizes.[37] Most systems use "weights" to change the parameters of the throughput and the varying connections to the neurons. Artificial neural networks can be autonomous and learn by input from outside "teachers" or even self-teaching from written-in rules. Theoretical properties[edit]Computational power[edit]The multi-layer perceptron (MLP) is a universal function approximator, as proven by the Cybenko theorem. However, the proof is not constructive regarding the number of neurons required or the settings of the weights. Work by Hava Siegelmann and Eduardo D. Sontag has provided a proof that a specific recurrent architecture with rational valued weights (as opposed to full precision real number-valued weights) has the full power of a Universal Turing Machine[38] using a finite number of neurons and standard linear connections. They have further shown that the use of irrational values for weights results in a machine with super-Turing power.[citation needed] Capacity[edit]Artificial neural network models have a property called 'capacity', which roughly corresponds to their ability to model any given function. It is related to the amount of information that can be stored in the network and to the notion of complexity. Convergence[edit]Nothing can be said in general about convergence since it depends on a number of factors. Firstly, there may exist many local minima. This depends on the cost function and the model. Secondly, the optimization method used might not be guaranteed to converge when far away from a local minimum. Thirdly, for a very large amount of data or parameters, some methods become impractical. In general, it has been found that theoretical guarantees regarding convergence are an unreliable guide to practical application.[citation needed] Generalization and statistics[edit]In applications where the goal is to create a system that generalizes well in unseen examples, the problem of over-training has emerged. This arises in convoluted or over-specified systems when the capacity of the network significantly exceeds the needed free parameters. There are two schools of thought for avoiding this problem: The first is to use cross-validation and similar techniques to check for the presence of overtraining and optimally select hyperparameters such as to minimize the generalization error. The second is to use some form of regularization. This is a concept that emerges naturally in a probabilistic (Bayesian) framework, where the regularization can be performed by selecting a larger prior probability over simpler models; but also in statistical learning theory, where the goal is to minimize over two quantities: the 'empirical risk' and the 'structural risk', which roughly corresponds to the error over the training set and the predicted error in unseen data due to overfitting.  Confidence analysis of a neural network Supervised neural networks that use an MSE cost function can use formal statistical methods to determine the confidence of the trained model. The MSE on a validation set can be used as an estimate for variance. This value can then be used to calculate the confidence interval of the output of the network, assuming a normal distribution. A confidence analysis made this way is statistically valid as long as the output probability distribution stays the same and the network is not modified. By assigning a softmax activation function, a generalization of the logistic function, on the output layer of the neural network (or a softmax component in a component-based neural network) for categorical target variables, the outputs can be interpreted as posterior probabilities. This is very useful in classification as it gives a certainty measure on classifications. The softmax activation function is:  Dynamic properties[edit] | | This article needs attention from an expert in Technology. Please add a reason or a talk parameter to this template to explain the issue with the article. WikiProject Technology (or its Portal) may be able to help recruit an expert. (November 2008) | Various techniques originally developed for studying disordered magnetic systems (i.e., the spin glass) have been successfully applied to simple neural network architectures, such as the Hopfield network. Influential work by E. Gardner and B. Derrida has revealed many interesting properties about perceptrons with real-valued synaptic weights, while later work by W. Krauth and M. Mezard has extended these principles to binary-valued synapses. Criticism[edit]A common criticism of neural networks, particularly in robotics, is that they require a large diversity of training for real-world operation. This is not surprising, since any learning machine needs sufficient representative examples in order to capture the underlying structure that allows it to generalize to new cases. Dean Pomerleau, in his research presented in the paper "Knowledge-based Training of Artificial Neural Networks for Autonomous Robot Driving," uses a neural network to train a robotic vehicle to drive on multiple types of roads (single lane, multi-lane, dirt, etc.). A large amount of his research is devoted to (1) extrapolating multiple training scenarios from a single training experience, and (2) preserving past training diversity so that the system does not become overtrained (if, for example, it is presented with a series of right turns – it should not learn to always turn right). These issues are common in neural networks that must decide from amongst a wide variety of responses, but can be dealt with in several ways, for example by randomly shuffling the training examples, by using a numerical optimization algorithm that does not take too large steps when changing the network connections following an example, or by grouping examples in so-called mini-batches. A. K. Dewdney, a former Scientific American columnist, wrote in 1997, "Although neural nets do solve a few toy problems, their powers of computation are so limited that I am surprised anyone takes them seriously as a general problem-solving tool." (Dewdney, p. 82) Arguments for Dewdney's position are that to implement large and effective software neural networks, much processing and storage resources need to be committed. While the brain has hardware tailored to the task of processing signals through a graph of neurons, simulating even a most simplified form on Von Neumann technology may compel a neural network designer to fill many millions of database rows for its connections – which can consume vast amounts of computer memory and hard disk space. Furthermore, the designer of neural network systems will often need to simulate the transmission of signals through many of these connections and their associated neurons – which must often be matched with incredible amounts of CPU processing power and time. While neural networks often yield effective programs, they too often do so at the cost of efficiency (they tend to consume considerable amounts of time and money). Arguments against Dewdney's position are that neural nets have been successfully used to solve many complex and diverse tasks, ranging from autonomously flying aircraft[39] to detecting credit card fraud[citation needed]. Technology writer Roger Bridgman commented on Dewdney's statements about neural nets: Neural networks, for instance, are in the dock not only because they have been hyped to high heaven, (what hasn't?) but also because you could create a successful net without understanding how it worked: the bunch of numbers that captures its behaviour would in all probability be "an opaque, unreadable table...valueless as a scientific resource". In spite of his emphatic declaration that science is not technology, Dewdney seems here to pillory neural nets as bad science when most of those devising them are just trying to be good engineers. An unreadable table that a useful machine could read would still be well worth having.[40]
In response to this kind of criticism, one should note that although it is true that analyzing what has been learned by an artificial neural network is difficult, it is much easier to do so than to analyze what has been learned by a biological neural network. Furthermore, researchers involved in exploring learning algorithms for neural networks are gradually uncovering generic principles which allow a learning machine to be successful. For example, Bengio and LeCun (2007) wrote an article regarding local vs non-local learning, as well as shallow vs deep architecture.[41] Some other criticisms came from believers of hybrid models (combining neural networks and symbolic approaches). They advocate the intermix of these two approaches and believe that hybrid models can better capture the mechanisms of the human mind (Sun and Bookman, 1990). Successes in pattern recognition contests since 2009[edit]Between 2009 and 2012, the recurrent neural networks and deep feedforward neural networks developed in the research group of Jürgen Schmidhuber at the Swiss AI Lab IDSIA have won eight international competitions in pattern recognition and machine learning.[42] For example, the bi-directional and multi-dimensional long short term memory (LSTM)[43][44] of Alex Graves et al. won three competitions in connected handwriting recognition at the 2009 International Conference on Document Analysis and Recognition (ICDAR), without any prior knowledge about the three different languages to be learned. Fast GPU-based implementations of this approach by Dan Ciresan and colleagues at IDSIA have won several pattern recognition contests, including the IJCNN 2011 Traffic Sign Recognition Competition,[45] the ISBI 2012 Segmentation of Neuronal Structures in Electron Microscopy Stacks challenge,[20] and others. Their neural networks also were the first artificial pattern recognizers to achieve human-competitive or even superhuman performance[21] on important benchmarks such as traffic sign recognition (IJCNN 2012), or the famous MNIST handwritten digits problem of Yann LeCun at NYU. Deep, highly nonlinear neural architectures similar to the 1980Neocognitron by Kunihiko Fukushima[17] and the "standard architecture of vision"[18] can also be pre-trained by unsupervised methods[46][47] of Geoff Hinton's lab at University of Toronto. A team from this lab won a 2012 contest sponsored by Merck to design software to help find molecules that might lead to new drugs.[48] Gallery[edit] -
-
A two-layer feedforward artificial neural network. -
-
See also[edit]References[edit] - Jump up^ McCulloch, Warren; Walter Pitts (1943). "A Logical Calculus of Ideas Immanent in Nervous Activity". Bulletin of Mathematical Biophysics 5 (4): 115–133. doi:10.1007/BF02478259.
- Jump up^ Hebb, Donald (1949). The Organization of Behavior. New York: Wiley.
- Jump up^ Farley, B; W.A. Clark (1954). "Simulation of Self-Organizing Systems by Digital Computer". IRE Transactions on Information Theory 4 (4): 76–84. doi:10.1109/TIT.1954.1057468.
- Jump up^ Rochester, N.; J.H. Holland, L.H. Habit, and W.L. Duda (1956). "Tests on a cell assembly theory of the action of the brain, using a large digital computer". IRE Transactions on Information Theory 2 (3): 80–93. doi:10.1109/TIT.1956.1056810.
- Jump up^ Rosenblatt, F. (1958). "The Perceptron: A Probalistic Model For Information Storage And Organization In The Brain".Psychological Review 65 (6): 386–408. doi:10.1037/h0042519. PMID 13602029.
- ^ Jump up to:a b Werbos, P.J. (1975). Beyond Regression: New Tools for Prediction and Analysis in the Behavioral Sciences.
- Jump up^ Minsky, M.; S. Papert (1969). An Introduction to Computational Geometry. MIT Press. ISBN 0-262-63022-2.
- Jump up^ Rumelhart, D.E; James McClelland (1986). Parallel Distributed Processing: Explorations in the Microstructure of Cognition. Cambridge: MIT Press.
- Jump up^ Russell, Ingrid. "Neural Networks Module". Retrieved 2012.
- Jump up^ Yang, J. J.; Pickett, M. D.; Li, X. M.; Ohlberg, D. A. A.; Stewart, D. R.; Williams, R. S. Nat. Nanotechnol. 2008, 3, 429–433.
- Jump up^ Strukov, D. B.; Snider, G. S.; Stewart, D. R.; Williams, R. S. Nature 2008, 453, 80–83.
- Jump up^ http://www.kurzweilai.net/how-bio-inspired-deep-learning-keeps-winning-competitions 2012 Kurzweil AI Interview withJürgen Schmidhuber on the eight competitions won by his Deep Learning team 2009–2012
- Jump up^ Graves, Alex; and Schmidhuber, Jürgen; Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks, in Bengio, Yoshua; Schuurmans, Dale; Lafferty, John; Williams, Chris K. I.; and Culotta, Aron (eds.), Advances in Neural Information Processing Systems 22 (NIPS'22), December 7th–10th, 2009, Vancouver, BC, Neural Information Processing Systems (NIPS) Foundation, 2009, pp. 545–552
- Jump up^ A. Graves, M. Liwicki, S. Fernandez, R. Bertolami, H. Bunke, J. Schmidhuber. A Novel Connectionist System for Improved Unconstrained Handwriting Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 5, 2009.
- Jump up^ http://www.scholarpedia.org/article/Deep_belief_networks /
- Jump up^ Hinton, G. E.; Osindero, S.; Teh, Y. (2006). "A fast learning algorithm for deep belief nets". Neural Computation 18 (7): 1527–1554. doi:10.1162/neco.2006.18.7.1527. PMID 16764513.
- ^ Jump up to:a b Fukushima, K. (1980). "Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position". Biological Cybernetics 36 (4): 93–202. doi:10.1007/BF00344251.
- ^ Jump up to:a b M Riesenhuber, T Poggio. Hierarchical models of object recognition in cortex. Nature neuroscience, 1999.
- Jump up^ D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber. Multi-Column Deep Neural Network for Traffic Sign Classification. Neural Networks, 2012.
- ^ Jump up to:a b D. Ciresan, A. Giusti, L. Gambardella, J. Schmidhuber. Deep Neural Networks Segment Neuronal Membranes in Electron Microscopy Images. In Advances in Neural Information Processing Systems (NIPS 2012), Lake Tahoe, 2012.
- ^ Jump up to:a b D. C. Ciresan, U. Meier, J. Schmidhuber. Multi-column Deep Neural Networks for Image Classification. IEEE Conf. on Computer Vision and Pattern Recognition CVPR 2012.
- Jump up^ "The Machine Learning Dictionary".
- Jump up^ Dominic, S., Das, R., Whitley, D., Anderson, C. (July 1991). "Genetic reinforcement learning for neural networks". IJCNN-91-Seattle International Joint Conference on Neural Networks. IJCNN-91-Seattle International Joint Conference on Neural Networks. Seattle, Washington, USA: IEEE. doi:10.1109/IJCNN.1991.155315. ISBN 0-7803-0164-1. Retrieved 29 July 2012.
- Jump up^ Hoskins, J.C.; Himmelblau, D.M. (1992). "Process control via artificial neural networks and reinforcement learning". Computers & Chemical Engineering 16 (4): 241–251. doi:10.1016/0098-1354(92)80045-B.
- Jump up^ Bertsekas, D.P., Tsitsiklis, J.N. (1996). Neuro-dynamic programming. Athena Scientific. p. 512. ISBN 1-886529-10-8.
- Jump up^ Secomandi, Nicola (2000). "Comparing neuro-dynamic programming algorithms for the vehicle routing problem with stochastic demands". Computers & Operations Research 27 (11–12): 1201–1225. doi:10.1016/S0305-0548(99)00146-X.
- Jump up^ de Rigo, D., Rizzoli, A. E., Soncini-Sessa, R., Weber, E., Zenesi, P. (2001). "Neuro-dynamic programming for the efficient management of reservoir networks". Proceedings of MODSIM 2001, International Congress on Modelling and Simulation.MODSIM 2001, International Congress on Modelling and Simulation. Canberra, Australia: Modelling and Simulation Society of Australia and New Zealand. doi:10.5281/zenodo.7481. ISBN 0-867405252. Retrieved 29 July 2012.
- Jump up^ Damas, M., Salmeron, M., Diaz, A., Ortega, J., Prieto, A., Olivares, G. (2000). "Genetic algorithms and neuro-dynamic programming: application to water supply networks". Proceedings of 2000 Congress on Evolutionary Computation. 2000 Congress on Evolutionary Computation. La Jolla, California, USA: IEEE. doi:10.1109/CEC.2000.870269. ISBN 0-7803-6375-2. Retrieved 29 July 2012.
- Jump up^ Deng, Geng; Ferris, M.C. (2008). "Neuro-dynamic programming for fractionated radiotherapy planning". Springer Optimization and Its Applications 12: 47–70. doi:10.1007/978-0-387-73299-2_3.
- Jump up^ de Rigo, D., Castelletti, A., Rizzoli, A.E., Soncini-Sessa, R., Weber, E. (January 2005). "A selective improvement technique for fastening Neuro-Dynamic Programming in Water Resources Network Management". In Pavel Zítek. Proceedings of the 16th IFAC World Congress – IFAC-PapersOnLine. 16th IFAC World Congress 16. Prague, Czech Republic: IFAC.doi:10.3182/20050703-6-CZ-1902.02172. ISBN 978-3-902661-75-3. Retrieved 30 December 2011.
- Jump up^ Ferreira, C. (2006). "Designing Neural Networks Using Gene Expression Programming". In A. Abraham, B. de Baets, M. Köppen, and B. Nickolay, eds., Applied Soft Computing Technologies: The Challenge of Complexity, pages 517–536, Springer-Verlag.
- Jump up^ Da, Y., Xiurun, G. (July 2005). T. Villmann, ed. "An improved PSO-based ANN with simulated annealing technique". New Aspects in Neurocomputing: 11th European Symposium on Artificial Neural Networks. Elsevier.doi:10.1016/j.neucom.2004.07.002. Retrieved 30 December 2011.
- Jump up^ Wu, J., Chen, E. (May 2009). Wang, H., Shen, Y., Huang, T., Zeng, Z., ed. "A Novel Nonparametric Regression Ensemble for Rainfall Forecasting Using Particle Swarm Optimization Technique Coupled with Artificial Neural Network". 6th International Symposium on Neural Networks, ISNN 2009. Springer. doi:10.1007/978-3-642-01513-7_6. ISBN 978-3-642-01215-0. Retrieved 1 January 2012.
- Jump up^ Roman M. Balabin, Ekaterina I. Lomakina (2009). "Neural network approach to quantum-chemistry data: Accurate prediction of density functional theory energies". J. Chem. Phys. 131 (7): 074104. doi:10.1063/1.3206326. PMID 19708729.
- Jump up^ Ganesan, N. "Application of Neural Networks in Diagnosing Cancer Disease Using Demographic Data". International Journal of Computer Applications.
- Jump up^ Bottaci, Leonardo. "Artificial Neural Networks Applied to Outcome Prediction for Colorectal Cancer Patients in Separate Institutions". The Lancet.
- Jump up^ "DANN:Genetic Wavelets". dANN project. Archived from the original on 21 August 2010. Retrieved 12 July 2010.
- Jump up^ Siegelmann, H.T.; Sontag, E.D. (1991). "Turing computability with neural nets". Appl. Math. Lett. 4 (6): 77–80.doi:10.1016/0893-9659(91)90080-F.
- Jump up^ NASA - Dryden Flight Research Center - News Room: News Releases: NASA NEURAL NETWORK PROJECT PASSES MILESTONE. Nasa.gov. Retrieved on 2013-11-20.
- Jump up^ Roger Bridgman's defence of neural networks
- Jump up^ http://www.iro.umontreal.ca/~lisa/publications2/index.php/publications/show/4
- Jump up^ 2012 Kurzweil AI Interview with Jürgen Schmidhuber on the eight competitions won by his Deep Learning team 2009–2012
- Jump up^ Graves, Alex; and Schmidhuber, Jürgen; Offline Handwriting Recognition with Multidimensional Recurrent Neural Networks, in Bengio, Yoshua; Schuurmans, Dale; Lafferty, John; Williams, Chris K. I.; and Culotta, Aron (eds.), Advances in Neural Information Processing Systems 22 (NIPS'22), 7–10 December 2009, Vancouver, BC, Neural Information Processing Systems (NIPS) Foundation, 2009, pp. 545–552.
- Jump up^ A. Graves, M. Liwicki, S. Fernandez, R. Bertolami, H. Bunke, J. Schmidhuber. A Novel Connectionist System for Improved Unconstrained Handwriting Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 31, no. 5, 2009.
- Jump up^ D. C. Ciresan, U. Meier, J. Masci, J. Schmidhuber. Multi-Column Deep Neural Network for Traffic Sign Classification. Neural Networks, 2012.
- Jump up^ Deep belief networks at Scholarpedia.
- Jump up^ Hinton, G. E.; Osindero, S.; Teh, Y. (2006). "A fast learning algorithm for deep belief nets". Neural Computation 18 (7): 1527–1554. doi:10.1162/neco.2006.18.7.1527. PMID 16764513.
- Jump up^ John Markoff, NY Times, November 23, 2012: Scientists See Promise in Deep-Learning Programs
Bibliography[edit] - Bhadeshia H. K. D. H. (1999). "Neural Networks in Materials Science". ISIJ International 39 (10): 966–979. doi:10.2355/isijinternational.39.966.
- Bishop, C.M. (1995) Neural Networks for Pattern Recognition, Oxford: Oxford University Press. ISBN 0-19-853849-9 (hardback) or ISBN 0-19-853864-2 (paperback)
- Cybenko, G.V. (1989). Approximation by Superpositions of a Sigmoidal function, Mathematics of Control, Signals, and Systems, Vol. 2 pp. 303–314. electronic version
- Duda, R.O., Hart, P.E., Stork, D.G. (2001) Pattern classification (2nd edition), Wiley, ISBN 0-471-05669-3
- Egmont-Petersen, M., de Ridder, D., Handels, H. (2002). "Image processing with neural networks – a review". Pattern Recognition 35 (10): 2279–2301. doi:10.1016/S0031-3203(01)00178-9.
- Gurney, K. (1997) An Introduction to Neural Networks London: Routledge. ISBN 1-85728-673-1 (hardback) or ISBN 1-85728-503-4 (paperback)
- Haykin, S. (1999) Neural Networks: A Comprehensive Foundation, Prentice Hall, ISBN 0-13-273350-1
- Fahlman, S, Lebiere, C (1991). The Cascade-Correlation Learning Architecture, created for National Science Foundation, Contract Number EET-8716324, and Defense Advanced Research Projects Agency (DOD), ARPA Order No. 4976 under Contract F33615-87-C-1499. electronic version
- Hertz, J., Palmer, R.G., Krogh. A.S. (1990) Introduction to the theory of neural computation, Perseus Books. ISBN 0-201-51560-1
- Lawrence, Jeanette (1994) Introduction to Neural Networks, California Scientific Software Press. ISBN 1-883157-00-5
- Masters, Timothy (1994) Signal and Image Processing with Neural Networks, John Wiley & Sons, Inc. ISBN 0-471-04963-8
- Ripley, Brian D. (1996) Pattern Recognition and Neural Networks, Cambridge
- Siegelmann, H.T. and Sontag, E.D. (1994). Analog computation via neural networks, Theoretical Computer Science, v. 131, no. 2, pp. 331–360. electronic version
- Sergios Theodoridis, Konstantinos Koutroumbas (2009) "Pattern Recognition", 4th Edition, Academic Press, ISBN 978-1-59749-272-0.
- Smith, Murray (1993) Neural Networks for Statistical Modeling, Van Nostrand Reinhold, ISBN 0-442-01310-8
- Wasserman, Philip (1993) Advanced Methods in Neural Computing, Van Nostrand Reinhold, ISBN 0-442-00461-3
- Computational Intelligence: A Methodological Introduction by Kruse, Borgelt, Klawonn, Moewes, Steinbrecher, Held, 2013, Springer, ISBN 9781447150121
- Neuro-Fuzzy-Systeme (3rd edition) by Borgelt, Klawonn, Kruse, Nauck, 2003, Vieweg, ISBN 9783528252656
External links[edit] |
+Citations (1) - CitationsAdd new citationList by: CiterankMapLink[1] Wikipedia
Author: Various
Cited by: Roger Yau 6:33 PM 18 October 2013 GMT
Citerank: (28) 291862AODE - Averaged one-dependence estimatorsAveraged one-dependence estimators (AODE) is a probabilistic classification learning technique. It was developed to address the attribute-independence problem of the popular naive Bayes classifier. It frequently develops substantially more accurate classifiers than naive Bayes at the cost of a modest increase in the amount of computation.109FDEF6, 291936BackpropagationBackpropagation, an abbreviation for "backward propagation of errors", is a common method of training artificial neural networks. From a desired output, the network learns from many inputs, similar to the way a child learns to identify a dog from examples of dogs.109FDEF6, 291937Bayesian statisticsBayesian statistics is a subset of the field of statistics in which the evidence about the true state of the world is expressed in terms of degrees of belief or, more specifically, Bayesian probabilities. Such an interpretation is only one of a number of interpretations of probability and there are other statistical techniques that are not based on "degrees of belief".109FDEF6, 291938Naive Bayes classifierA naive Bayes classifier is a simple probabilistic classifier based on applying Bayes' theorem with strong (naive) independence assumptions. A more descriptive term for the underlying probability model would be "independent feature model". An overview of statistical classifiers is given in the article on Pattern recognition.109FDEF6, 291939Bayesian networkA Bayesian network, Bayes network, belief network, Bayes(ian) model or probabilistic directed acyclic graphical model is a probabilistic graphical model (a type of statistical model) that represents a set of random variables and their conditional dependencies via a directed acyclic graph (DAG). For example, a Bayesian network could represent the probabilistic relationships between diseases and symptoms. 109FDEF6, 291941Case-based reasoningCase-based reasoning (CBR), broadly construed, is the process of solving new problems based on the solutions of similar past problems. An auto mechanic who fixes an engine by recalling another car that exhibited similar symptoms is using case-based reasoning. So, too, an engineer copying working elements of nature (practicing biomimicry), is treating nature as a database of solutions to problems. Case-based reasoning is a prominent kind of analogy making.109FDEF6, 291942Decision tree learningDecision tree learning uses a decision tree as a predictive model which maps observations about an item to conclusions about the item's target value. It is one of the predictive modelling approaches used in statistics, data mining and machine learning. More descriptive names for such tree models are classification trees or regression trees. In these tree structures, leaves represent class labels and branches represent conjunctions of features that lead to those class labels.109FDEF6, 291943Inductive logic programmingInductive logic programming (ILP) is a subfield of machine learning which uses logic programming as a uniform representation for examples, background knowledge and hypotheses. Given an encoding of the known background knowledge and a set of examples represented as a logical database of facts, an ILP system will derive a hypothesised logic program which entails all the positive and none of the negative examples.109FDEF6, 291944Gaussian process regression (Kriging)Kriging is a method to build an approximation of a function from a set of evaluations of the function at a finite set of points. The method originates from the domain of geostatistics and is now widely used in the domain of spatial analysis and computer experiments. The technique is also known as Gaussian process regression, Kolmogorov Wiener prediction, or Best Linear Unbiased Prediction.109FDEF6, 291945Gene expression programmingGene expression programming (GEP) is an evolutionary algorithm that creates computer programs or models. These computer programs are complex tree structures that learn and adapt by changing their sizes, shapes, and composition, much like a living organism. And like living organisms, the computer programs of GEP are also encoded in simple linear chromosomes of fixed length. Thus, GEP is a genotype-phenotype system.109FDEF6, 291946Group method of data handlingGroup method of data handling (GMDH) is a family of inductive algorithms for computer-based mathematical modeling of multi-parametric datasets that features fully automatic structural and parametric optimization of models.109FDEF6, 291947Learning automataA branch of the theory of adaptive control is devoted to learning automata surveyed by Narendra and Thathachar which were originally described explicitly as finite state automata. Learning automata select their current action based on past experiences from the environment.109FDEF6, 291948Supervised learningSupervised learning is the machine learning task of inferring a function from labeled training data.[1] The training data consist of a set of training examples. In supervised learning, each example is a pair consisting of an input object (typically a vector) and a desired output value (also called the supervisory signal). A supervised learning algorithm analyzes the training data and produces an inferred function, which can be used for mapping new examples. 25CBCBFF, 291950Unsupervised learningIn machine learning, the problem of unsupervised learning is that of trying to find hidden structure in unlabeled data. Since the examples given to the learner are unlabeled, there is no error or reward signal to evaluate a potential solution. This distinguishes unsupervised learning from supervised learning and reinforcement learning.25CBCBFF, 291951Reinforcement learningReinforcement learning is an area of machine learning inspired by behaviorist psychology, concerned with how software agents ought to take actions in an environment so as to maximize some notion of cumulative reward. The problem, due to its generality, is studied in many other disciplines, such as game theory, control theory, operations research, information theory, simulation-based optimization, statistics, and genetic algorithms.25CBCBFF, 292450Hierarchical clusteringIn data mining, hierarchical clustering is a method of cluster analysis which seeks to build a hierarchy of clusters. Strategies for hierarchical clustering generally fall into two types:
Agglomerative: This is a "bottom up" approach: each observation starts in its own cluster, and pairs of clusters are merged as one moves up the hierarchy.
Divisive: This is a "top down" approach: all observations start in one cluster, and splits are performed recursively as one moves down the hierarch109FDEF6, 292451Association rule learningAssociation rule learning is a popular and well researched method for discovering interesting relations between variables in large databases. It is intended to identify strong rules discovered in databases using different measures of interestingness.109FDEF6, 292454Others25CBCBFF, 292455Learning Vector QuantizationIn computer science, Learning Vector Quantization (LVQ), is a prototype-based supervised classification algorithm. LVQ is the supervised counterpart of vector quantization systems.
LVQ can be understood as a special case of an artificial neural network, more precisely, it applies a winner-take-all Hebbian learning-based approach. It is a precursor to Self-organizing maps (SOM) and related to Neural gas, and to the k-Nearest Neighbor algorithm (k-NN). LVQ was invented by Teuvo Kohonen.109FDEF6, 292463Logistic Model TreeLMT is a classification model with an associated supervised training algorithm that combines logistic regression (LR) and decision tree learning. Logistic model trees are based on the earlier idea of a model tree: a decision tree that has linear regression models at its leaves to provide a piecewise linear regression model (where ordinary decision trees with constants at their leaves would produce a piecewise constant model).109FDEF6, 292464Minimum message lengthMinimum message length (MML) is a formal information theory restatement of Occam's Razor: even when models are not equal in goodness of fit accuracy to the observed data, the one generating the shortest overall message is more likely to be correct (where the message consists of a statement of the model, followed by a statement of data encoded concisely using that model). MML was invented by Chris Wallace, first appearing in the seminal (Wallace and Boulton, 1968).109FDEF6, 292465Lazy learningIn artificial intelligence, lazy learning is a learning method in which generalization beyond the training data is delayed until a query is made to the system, as opposed to in eager learning, where the system tries to generalize the training data before receiving queries.109FDEF6, 292466Instance-based learninginstance-based learning or memory-based learning is a family of learning algorithms that, instead of performing explicit generalization, compare new problem instances with instances seen in training, which have been stored in memory. Instance-based learning is a kind of lazy learning.109FDEF6, 292475k-nearest neighbor algorithmIn pattern recognition, the k-nearest neighbor algorithm (k-NN) is a non-parametric method for classifying objects based on closest training examples in the feature space. k-NN is a type of instance-based learning, or lazy learning where the function is only approximated locally and all computation is deferred until classification. 109FDEF6, 292476Analogical modelingAnalogical modeling (hereafter AM) is a formal theory of exemplar-based analogical reasoning, proposed by Royal Skousen, professor of Linguistics and English language at Brigham Young University in Provo, Utah. It is applicable to language modeling and other categorization tasks. Analogical modeling is related to connectionism and nearest neighbor approaches, in that it is data-based rather than abstraction-based.109FDEF6, 292478Probably approximately correct learningIn this framework, the learner receives samples and must select a generalization function (called the hypothesis) from a certain class of possible functions. The goal is that, with high probability (the "probably" part), the selected function will have low generalization error (the "approximately correct" part). The learner must be able to learn the concept given any arbitrary approximation ratio, probability of success, or distribution of the samples.109FDEF6, 292480Ripple-down rulesRipple Down Rules is a way of approaching knowledge acquisition. Knowledge acquisition refers to the transfer of knowledge from human experts to knowledge based systems.109FDEF6, 292481Support vector machinesIn machine learning, support vector machines (SVMs, also support vector networks[1]) are supervised learning models with associated learning algorithms that analyze data and recognize patterns, used for classification and regression analysis. 109FDEF6 URL: |
|
|