Dominance-based rough set approach (DRSA) is an extension of rough set theory for multi-criteria decision analysis (MCDA), introduced by Greco, Matarazzo and Słowiński.[1][2][3] The main change comparing to the classical rough sets is the substitution of the indiscernibility relation by a dominance relation, which permits to deal with inconsistencies typical to consideration of criteria and preference-ordered decision classes.
Contents
[hide] - 1 Multicriteria classification (sorting)
- 2 Data representation
- 2.1 Decision table
- 2.2 Outranking relation
- 2.3 Decision classes and class unions
- 3 Main concepts
- 3.1 Dominance
- 3.2 Rough approximations
- 3.3 Quality of approximation and reducts
- 4 Decision rules
- 5 Example
- 6 Extensions
- 6.1 Multicriteria choice and ranking problems
- 6.2 Variable-consistency DRSA
- 6.3 Stochastic DRSA
- 7 Software
- 8 See also
- 9 References
- 10 External links
Multicriteria classification (sorting)[edit]
Multicriteria classification (sorting) is one of the problems considered within MCDA and can be stated as follows: given a set of objects evaluated by a set of criteria (attributes with preference-order domains), assign these objects to some pre-defined and preference-ordered decision classes, such that each object is assigned to exactly one class. Due to the preference ordering, improvement of evaluations of an object on the criteria should not worsen its class assignment. The sorting problem is very similar to the problem of classification, however, in the latter, the objects are evaluated by regular attributes and the decision classes are not necessarily preference ordered. The problem of multicriteria classification is also referred to as ordinal classification problem with monotonicity constraints and often appears in real-life application when ordinal and monotone properties follow from the domain knowledge about the problem.
As an illustrative example, consider the problem of evaluation in a high school. The director of the school wants to assign students (objects) to three classes: bad, medium and good (notice that class good is preferred to medium and medium is preferred tobad). Each student is described by three criteria: level in Physics, Mathematics and Literature, each taking one of three possible values bad, medium and good. Criteria are preference-ordered and improving the level from one of the subjects should not result in worse global evaluation (class).
As a more serious example, consider classification of bank clients, from the viewpoint of bankruptcy risk, into classes safe and risky. This may involve such characteristics as "return on equity (ROE)", "return on investment (ROI)" and "return on sales (ROS)". The domains of these attributes are not simply ordered but involve a preference order since, from the viewpoint of bank managers, greater values of ROE, ROI or ROS are better for clients being analysed for bankruptcy risk . Thus, these attributes are criteria. Neglecting this information in knowledge discovery may lead to wrong conclusions.
Data representation[edit]
Decision table[edit]
In DRSA, data are often presented using a particular form of decision table. Formally, a DRSA decision table is a 4-tuple 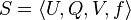 , where
, where  is a finite set of objects,
is a finite set of objects, 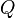 is a finite set of criteria,
is a finite set of criteria,  where
where  is the domain of the criterion
is the domain of the criterion 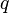 and
and  is an information function such that
is an information function such that 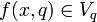 for every
for every 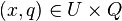 . The set is divided into condition criteria (set
. The set is divided into condition criteria (set 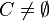 ) and the decision criterion (class)
) and the decision criterion (class)  . Notice, that
. Notice, that 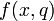 is an evaluation of object
is an evaluation of object 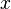 on criterion
on criterion 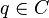 , while
, while 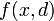 is the class assignment (decision value) of the object. An example of decision table is shown in Table 1 below.
is the class assignment (decision value) of the object. An example of decision table is shown in Table 1 below.
Outranking relation[edit]
It is assumed that the domain of a criterion 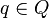 is completely preordered by an outranking relation
is completely preordered by an outranking relation 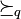 ;
;  means that is at least as good as (outranks)
means that is at least as good as (outranks) 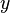 with respect to the criterion . Without loss of generality, we assume that the domain of is a subset of reals,
with respect to the criterion . Without loss of generality, we assume that the domain of is a subset of reals, 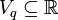 , and that the outranking relation is a simple order between real numbers
, and that the outranking relation is a simple order between real numbers  such that the following relation holds:
such that the following relation holds: 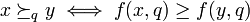 . This relation is straightforward for gain-type ("the more, the better") criterion, e.g. company profit. For cost-type ("the less, the better") criterion, e.g. product price, this relation can be satisfied by negating the values from .
. This relation is straightforward for gain-type ("the more, the better") criterion, e.g. company profit. For cost-type ("the less, the better") criterion, e.g. product price, this relation can be satisfied by negating the values from .
Decision classes and class unions[edit]
Let 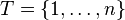 . The domain of decision criterion,
. The domain of decision criterion,  consist of
consist of 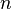 elements (without loss of generality we assume
elements (without loss of generality we assume 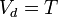 ) and induces a partition of into classes
) and induces a partition of into classes 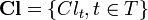 , where
, where  . Each object
. Each object  is assigned to one and only one class
is assigned to one and only one class  . The classes are preference-ordered according to an increasing order of class indices, i.e. for all
. The classes are preference-ordered according to an increasing order of class indices, i.e. for all 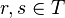 such that
such that 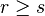 , the objects from
, the objects from 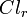 are strictly preferred to the objects from
are strictly preferred to the objects from 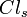 . For this reason, we can consider the upward and downward unions of classes, defined respectively, as:
. For this reason, we can consider the upward and downward unions of classes, defined respectively, as:
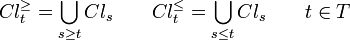
Main concepts[edit]
Dominance[edit]
We say that dominates with respect to 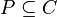 , denoted by
, denoted by  , if is better than on every criterion from
, if is better than on every criterion from 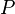 ,
, 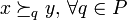 . For each , the dominance relation
. For each , the dominance relation  is reflexive and transitive, i.e. it is a partial pre-order. Given and , let
is reflexive and transitive, i.e. it is a partial pre-order. Given and , let
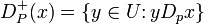
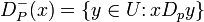
represent P-dominating set and P-dominated set with respect to , respectively.
Rough approximations[edit]
The key idea of the rough set philosophy is approximation of one knowledge by another knowledge. In DRSA, the knowledge being approximated is a collection of upward and downward unions of decision classes and the "granules of knowledge" used for approximation are P-dominating and P-dominated sets.
The P-lower and the P-upper approximation of 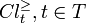 with respect to , denoted as
with respect to , denoted as  and
and  , respectively, are defined as:
, respectively, are defined as:
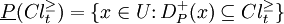

Analogously, the P-lower and the P-upper approximation of 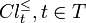 with respect to , denoted as
with respect to , denoted as 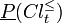 and
and  , respectively, are defined as:
, respectively, are defined as:


Lower approximations group the objects which certainly belong to class union 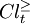 (respectively
(respectively  ). This certainty comes from the fact, that object belongs to the lower approximation (respectively ), if no other object in contradicts this claim, i.e. every object
). This certainty comes from the fact, that object belongs to the lower approximation (respectively ), if no other object in contradicts this claim, i.e. every object 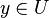 which P-dominates , also belong to the class union (respectively ). Upper approximations group the objects which could belong to (respectively ), since object belongs to the upper approximation (respectively ), if there exist another object P-dominated by from class union (respectively ).
which P-dominates , also belong to the class union (respectively ). Upper approximations group the objects which could belong to (respectively ), since object belongs to the upper approximation (respectively ), if there exist another object P-dominated by from class union (respectively ).
The P-lower and P-upper approximations defined as above satisfy the following properties for all  and for any :
and for any :
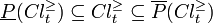
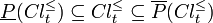
The P-boundaries (P-doubtful regions) of and are defined as:

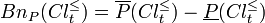
Quality of approximation and reducts[edit]
The ratio

defines the quality of approximation of the partition  into classes by means of the set of criteria . This ratio express the relation between all the P-correctly classified objects and all the objects in the table.
into classes by means of the set of criteria . This ratio express the relation between all the P-correctly classified objects and all the objects in the table.
Every minimal subset such that 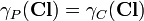 is called a reduct of
is called a reduct of  and is denoted by
and is denoted by  . A decision table may have more than one reduct. The intersection of all reducts is known as the core.
. A decision table may have more than one reduct. The intersection of all reducts is known as the core.
Decision rules[edit]
On the basis of the approximations obtained by means of the dominance relations, it is possible to induce a generalized description of the preferential information contained in the decision table, in terms of decision rules. The decision rules are expressions of the form if [condition] then [consequent], that represent a form of dependency between condition criteria and decision criteria. Procedures for generating decision rules from a decision table use an inducive learning principle. We can distinguish three types of rules: certain, possible and approximate. Certain rules are generated from lower approximations of unions of classes; possible rules are generated from upper approximations of unions of classes and approximate rules are generated from boundary regions.
Certain rules has the following form:
if  and
and 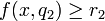 and
and 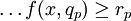 then
then 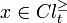
if 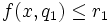 and
and 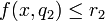 and
and  then
then 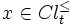
Possible rules has a similar syntax, however the consequent part of the rule has the form: could belong to or the form: could belong to .
Finally, approximate rules has the syntax:
if and and 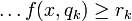 and
and 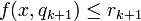 and
and  and then
and then 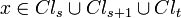
The certain, possible and approximate rules represent certain, possible and ambiguous knowledge extracted from the decision table.
Each decision rule should be minimal. Since a decision rule is an implication, by a minimal decision rule we understand such an implication that there is no other implication with an antecedent of at least the same weakness (in other words, rule using a subset of elementary conditions or/and weaker elementary conditions) and a consequent of at least the same strength (in other words, rule assigning objects to the same union or sub-union of classes).
A set of decision rules is complete if it is able to cover all objects from the decision table in such a way that consistent objects are re-classified to their original classes and inconsistent objects are classified to clusters of classes referring to this inconsistency. We call minimal each set of decision rules that is complete and non-redundant, i.e. exclusion of any rule from this set makes it non-complete. One of three induction strategies can be adopted to obtain a set of decision rules:[4]
- generation of a minimal description, i.e. a minimal set of rules,
- generation of an exhaustive description, i.e. all rules for a given data matrix,
- generation of a characteristic description, i.e. a set of rules covering relatively many objects each, however, all together not necessarily all objects from the decision table
The most popular rule induction algorithm for dominance-based rough set approach is DOMLEM,[5] which generates minimal set of rules.
Example[edit]
Consider the following problem of high school students evaluations:
-
Table 1: Example—High School Evaluations | object (student) | 
(Mathematics) | 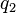
(Physics) | 
(Literature) | | 
(global score) |
 | medium | medium | bad | | bad |
 | good | medium | bad | | medium |
 | medium | good | bad | | medium |
 | bad | medium | good | | bad |
 | bad | bad | medium | | bad |
 | bad | medium | medium | | medium |
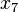 | good | good | bad | | good |
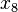 | good | medium | medium | | medium |
 | medium | medium | good | | good |
 | good | medium | good | | good |
Each object (student) is described by three criteria 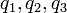 , related to the levels in Mathematics, Physics and Literature, respectively. According to the decision attribute, the students are divided into three preference-ordered classes:
, related to the levels in Mathematics, Physics and Literature, respectively. According to the decision attribute, the students are divided into three preference-ordered classes:  ,
, 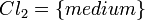 and
and 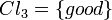 . Thus, the following unions of classes were approximated:
. Thus, the following unions of classes were approximated:
 i.e. the class of (at most) bad students,
i.e. the class of (at most) bad students,
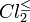 i.e. the class of at most medium students,
i.e. the class of at most medium students,
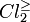 i.e. the class of at least medium students,
i.e. the class of at least medium students,
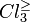 i.e. the class of (at least) good students.
i.e. the class of (at least) good students.
Notice that evaluations of objects 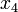 and
and 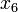 are inconsistent, because has better evaluations on all three criteria than but worse global score.
are inconsistent, because has better evaluations on all three criteria than but worse global score.
Therefore, lower approximations of class unions consist of the following objects:
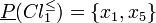
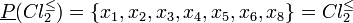
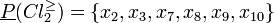

Thus, only classes and cannot be approximated precisely. Their upper approximations are as follows:

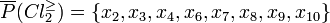
while their boundary regions are:

Of course, since and are approximated precisely, we have  ,
,  and
and 
The following minimal set of 10 rules can be induced from the decision table:
- if
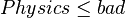 then
then 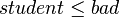
- if
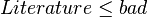 and
and 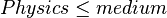 and
and 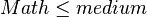 then
then - if
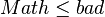 then
then 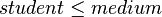
- if
 and then
and then - if and then
- if
 and
and  then
then 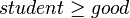
- if
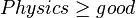 and
and 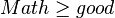 then
then - if then

- if then
- if and
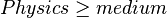 then
then 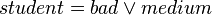
The last rule is approximate, while the rest are certain.
Extensions[edit]
Multicriteria choice and ranking problems[edit]
The other two problems considered within multi-criteria decision analysis, multicriteria choice and ranking problems, can also be solved using dominance-based rough set approach. This is done by converting the decision table into pairwise comparison table(PCT).[1]
Variable-consistency DRSA[edit]
The definitions of rough approximations are based on a strict application of the dominance principle. However, when defining non-ambiguous objects, it is reasonable to accept a limited proportion of negative examples, particularly for large decision tables. Such extended version of DRSA is called Variable-Consistency DRSA model (VC-DRSA)[6]
Stochastic DRSA[edit]
In real-life data, particularly for large datasets, the notions of rough approximations were found to be excessively restrictive. Therefore an extension of DRSA, based on stochastic model (Stochastic DRSA), which allows inconsistencies to some degree, has been introduced.[7] Having stated the probabilistic model for ordinal classification problems with monotonicity constraints, the concepts of lower approximations are extended to the stochastic case. The method is based on estimating the conditional probabilities using the nonparametric maximum likelihood method which leads to the problem of isotonic regression.
Stochastic dominance-based rough sets can also be regarded as a sort of variable-consistency model.
Software[edit]
4eMka2 is a decision support system for multiple criteria classification problems based on dominance-based rough sets (DRSA). JAMM is a much more advanced successor of 4eMka2. Both systems are freely available for non-profit purposes on theLaboratory of Intelligent Decision Support Systems (IDSS) website.
See also[edit]
References[edit]
- ^ Jump up to:a b Greco, S., Matarazzo, B., Słowiński, R.: Rough sets theory for multi-criteria decision analysis. European Journal of Operational Research, 129, 1 (2001) 1–47
- Jump up^ Greco, S., Matarazzo, B., Słowiński, R.: Multicriteria classification by dominance-based rough set approach. In: W.Kloesgen and J.Zytkow (eds.), Handbook of Data Mining and Knowledge Discovery, Oxford University Press, New York, 2002
- Jump up^ Słowiński, R., Greco, S., Matarazzo, B.: Rough set based decision support. Chapter 16 [in]: E.K. Burke and G. Kendall (eds.), Search Methodologies: Introductory Tutorials in Optimization and Decision Support Techniques, Springer-Verlag , New York (2005) 475–527
- Jump up^ Stefanowski, J.: On rough set based approach to induction of decision rules. In Skowron, A., Polkowski, L. (eds.): Rough Set in Knowledge Discovering, Physica Verlag, Heidelberg (1998) 500--529
- Jump up^ Greco S., Matarazzo, B., Słowiński, R., Stefanowski, J.: An Algorithm for Induction of Decision Rules Consistent with the Dominance Principle. In W. Ziarko, Y. Yao (eds.): Rough Sets and Current Trends in Computing. Lecture Notes in Artificial Intelligence 2005 (2001) 304--313. Springer-Verlag
- Jump up^ Greco, S., B. Matarazzo, R. Slowinski and J. Stefanowski: Variable consistency model of dominance-based rough set approach. In W.Ziarko, Y.Yao (eds.): Rough Sets and Current Trends in Computing. Lecture Notes in Artificial Intelligence 2005 (2001) 170–181. Springer-Verlag
- Jump up^ Dembczyński, K., Greco, S., Kotłowski, W., Słowiński, R.: Statistical model for rough set approach to multicriteria classification. In Kok, J.N., Koronacki, J., de Mantaras, R.L., Matwin, S., Mladenic, D., Skowron, A. (eds.): Knowledge Discovery in Databases: PKDD 2007, Warsaw, Poland. Lecture Notes in Computer Science 4702 (2007) 164–175.
External links[edit]