
Diagram of a restricted Boltzmann machine with three visible units and four hidden units (no bias units).
A restricted Boltzmann machine (RBM) is a generative stochastic neural network that can learn a probability distribution over its set of inputs. RBMs were initially invented under the name Harmonium by Paul Smolensky in 1986,[1] but only rose to prominence after Geoffrey Hinton and collaborators invented fast learning algorithms for them in the mid-2000s. RBMs have found applications in dimensionality reduction,[2]classification,[3] collaborative filtering, feature learning[4] and topic modelling.[5] They can be trained in either supervised or unsupervised ways, depending on the task.
As their name implies, RBMs are a variant of Boltzmann machines, with the restriction that their neurons must form a bipartite graph: they have input units, corresponding to features of their inputs, hidden units that are trained, and each connection in an RBM must connect a visible unit to a hidden unit. (By contrast, "unrestricted" Boltzmann machines may have connections between hidden units, making them recurrent networks.) This restriction allows for more efficient training algorithms than are available for the general class of Boltzmann machines, in particular the gradient-based contrastive divergence algorithm.[6]
Restricted Boltzmann machines can also be used in deep learning networks. In particular, deep belief networks can be formed by "stacking" RBMs in a particular way, and the weights of these can in turn be used to initialize the weights of multilayer perceptrons trained with backpropagation.[7]
Structure[edit]
The standard type of RBM has binary-valued (Boolean) hidden and visible units, and consists of a symmetric matrix of weights  associated with the connection between hidden unit
associated with the connection between hidden unit  and visible unit
and visible unit 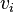 , as well as bias weights (offsets)
, as well as bias weights (offsets) 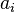 for the visible units and
for the visible units and  for the hidden units. Given these, the energy of a configuration
for the hidden units. Given these, the energy of a configuration 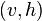 can be computed as
can be computed as
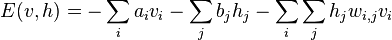
or, in vector form,
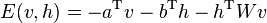
This energy function is analogous to that of a Hopfield network. As in general Boltzmann machines, probability distributions over hidden and/or visible vectors are defined in terms of the energy function:[8]
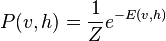
where 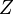 is a partition function defined as the sum of
is a partition function defined as the sum of  over all possible configurations (in other words, just a normalizing constant to ensure the probability distribution sums to 1). Similarly, the (marginal) probability of a visible (input) vector of booleans is the sum over all possible hidden layer configurations:[8]
over all possible configurations (in other words, just a normalizing constant to ensure the probability distribution sums to 1). Similarly, the (marginal) probability of a visible (input) vector of booleans is the sum over all possible hidden layer configurations:[8]
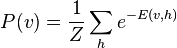
Since the RBM has the shape of a bipartite graph, with no intra-layer connections, the hidden unit activations are mutually independent given the visible unit activations and conversely, the visible unit activations are mutually independent given the hidden unit activations.[6] That is, for  visible units and
visible units and  hidden units,
hidden units,
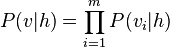

and the individual activation probabilities are given by

and
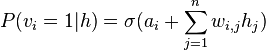
where  denotes the logistic sigmoid.
denotes the logistic sigmoid.
Relation to other models[edit]
Restricted Boltzmann machines are a special case of Boltzmann machines and Markov random fields.[9][10] Their graphical model corresponds to that of factor analysis.[11]
Training algorithm[edit]
Restricted Boltzmann machines are trained to maximize the product of probabilities assigned to some training set 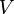 (a matrix, each row of which is treated as a visible vector
(a matrix, each row of which is treated as a visible vector  ),
),

or equivalently, to maximize the expected log probability of :[9][10]
![\arg\max_W \mathbb{E} \left[\sum_{v \in V} \log P(v)\right]](http://upload.wikimedia.org/math/7/e/2/7e291199caa7b55e4ade270607adbdd7.png)
The algorithm most often used to train RBMs, that is, to optimize the weight vector  , is the contrastive divergence (CD) algorithm due to Hinton, originally developed to train product of experts models.[12] The algorithm performs Gibbs sampling and is used inside a gradient descent procedure (similar to the way backpropagation is used inside such a procedure when training feedforward neural nets) to compute weight update.
, is the contrastive divergence (CD) algorithm due to Hinton, originally developed to train product of experts models.[12] The algorithm performs Gibbs sampling and is used inside a gradient descent procedure (similar to the way backpropagation is used inside such a procedure when training feedforward neural nets) to compute weight update.
The basic, single-step contrastive divergence (CD-1) procedure for a single sample can be summarized as follows:
- Take a training sample , compute the probabilities of the hidden units and sample a hidden activation vector
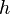 from this probability distribution.
from this probability distribution. - Compute the outer product of and and call this the positive gradient.
- From , sample a reconstruction
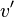 of the visible units, then resample the hidden activations
of the visible units, then resample the hidden activations 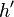 from this.
from this. - Compute the outer product of and and call this the negative gradient.
- Let the weight update to
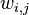 be the positive gradient minus the negative gradient, times some learning rate.
be the positive gradient minus the negative gradient, times some learning rate.
See also[edit]
References[edit]
- Jump up^ Smolensky, Paul (1986). "Chapter 6: Information Processing in Dynamical Systems: Foundations of Harmony Theory". In Rumelhart, David E.; McLelland, James L. Parallel Distributed Processing: Explorations in the Microstructure of Cognition, Volume 1: Foundations. MIT Press. pp. 194–281. ISBN 0-262-68053-X.
- Jump up^ Hinton, G. E.; Salakhutdinov, R. R. (2006). "Reducing the Dimensionality of Data with Neural Networks". Science313 (5786): 504–507. doi:10.1126/science.1127647.PMID 16873662. edit
- Jump up^ Larochelle, H.; Bengio, Y. (2008). "Classification using discriminative restricted Boltzmann machines".Proceedings of the 25th international conference on Machine learning - ICML '08. p. 536.doi:10.1145/1390156.1390224. ISBN 9781605582054.edit
- Jump up^ Coates, Adam; Lee, Honglak; Ng, Andrew Y. (2011). "An analysis of single-layer networks in unsupervised feature learning". International Conference on Artificial Intelligence and Statistics (AISTATS).
- Jump up^ Ruslan Salakhutdinov and Geoffrey Hinton (2010).Replicated softmax: an undirected topic model. Neural Information Processing Systems 23.
- ^ Jump up to:a b Miguel Á. Carreira-Perpiñán and Geoffrey Hinton (2005). On contrastive divergence learning. Artificial Intelligence and Statistics.
- Jump up^ Deep Belief Networks in Deep Learning Tutorials.
- ^ Jump up to:a b Geoffrey Hinton (2010). A Practical Guide to Training Restricted Boltzmann Machines. UTML TR 2010–003, University of Toronto.
- ^ Jump up to:a b Sutskever, Ilya; Tieleman, Tijmen (2010). "On the convergence properties of contrastive divergence". Proc. 13th Int'l Conf. on AI and Statistics (AISTATS).
- ^ Jump up to:a b Asja Fischer and Christian Igel. Training Restricted Boltzmann Machines: An Introduction. Pattern Recognition 47, pp. 25-39, 2014
- Jump up^ María Angélica Cueto; Jason Morton; Bernd Sturmfels (2010). "Geometry of the restricted Boltzmann machine".Algebraic Methods in Statistics and Probability (American Mathematical Society) 516. arXiv:0908.4425.
- Jump up^ Hinton, G. E. (2002). "Training Products of Experts by Minimizing Contrastive Divergence". Neural Computation 14 (8): 1771–1800.doi:10.1162/089976602760128018. PMID 12180402.edit
External links[edit]