|
![]()
Eclat algorithm Τμήμα Άποψης
1 #302726Eclat is a depth-first search algorithm using set intersection. The Eclat algorithm is used to perform itemset mining. Itemset mining let us find frequent patterns in data like if a consumer buys milk, he also buys bread. This type of pattern is called association rules and is used in many application domains. | The Eclat Algorithm[edit]The Eclat algorithm is used to perform itemset mining. Itemset mining let us find frequent patterns in data like if a consumer buys milk, he also buys bread. This type of pattern is called association rules and is used in many application domains. The basic idea for the eclat algorithm is use tidset intersections to compute the support of a candidate itemset avoiding the generation of subsets that does not exist in the prefix tree. Algorithm[edit]The Eclat algorithm is defined recursively. The initial call use all the single items with their tidsets. In each recursive call, the function IntersectTidsets verifies each itemset-tidset pair  with all the others pairs with all the others pairs 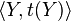 to generate new candidates to generate new candidates 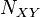 . If the new candidate is frequent, it is added to the set . If the new candidate is frequent, it is added to the set 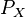 . Then, recursively, it finds all the frequent itemsets in the . Then, recursively, it finds all the frequent itemsets in the  branch. The algorithm searchs in a DFS manner to find all the frequent sets. branch. The algorithm searchs in a DFS manner to find all the frequent sets. Implementation[edit]The eclat algorithm can be found in the arule package of R system. * R package: arules * Method: eclat * Documentation : arules package Usage eclat(data, parameter = NULL, control = NULL) Arguments - data
- object of class transactions or any data structure which can be coerced into transactions (e.g., binary matrix, data.frame).
- parameter
- object of class ECparameter or named list (default values are: support 0.1 and maxlen 5)
- control
- object of class ECcontrol or named list for algorithmic controls.
Value Returns an object of class itemsets Example data("Adult") ## Mine itemsets with minimum support of 0.1.itemsets <- eclat(Adult, parameter = list(supp = 0.1, maxlen = 15))Visualization[edit]The arules package implements some visualization methods for itemsets, which are the return type for the eclat algorithm. Here are some examples: Example 1 data("Adult") ## Mine frequent itemsets with Eclat.fsets <- eclat(Adult, parameter = list(supp = 0.5)) ## Display the 5 itemsets with the highest support.fsets.top5 <- SORT(fsets)1:5?inspect(fsets.top5) ## Get the itemsets as a listas(items(fsets.top5), "list") ## Get the itemsets as a binary matrixas(items(fsets.top5), "matrix") ## Get the itemsets as a sparse matrix, a ngCMatrix from package Matrix.## Warning: for efficiency reasons, the ngCMatrix you get is transposedas(items(fsets.top5), "ngCMatrix")Example 2 ## Create transaction data set.data <- list( c("a","b","c"), c("a","b"), c("a","b","d"), c("b","e"), c("b","c","e"), c("a","d","e"), c("a","c"), c("a","b","d"), c("c","e"), c("a","b","d","e")) t <- as(data, "transactions") ## Mine itemsets with tidLists.f <- eclat(data, parameter = list(support = 0, tidLists = TRUE)) ## Get dimensions of the tidLists.dim(tidLists(f)) ## Coerce tidLists to list.as(tidLists(f), "list") ## Inspect visually.image(tidLists(f)) ##Show the Frequent itemsets and respectives supportsinspect(f) | # | items | support | | 1 | {b, c, e} | 0.1 | | 2 | {a, b, c} | 0.1 | | 3 | {a, c} | 0.2 | | 4 | {b, c} | 0.2 | | 5 | {c, e} | 0.2 | | 6 | {a, b,d, e} | 0.1 | | 7 | {a, d, e} | 0.2 | | 8 | {b, d, e} | 0.1 | | 9 | {a, b, d} | 0.3 | | 10 | {a, d} | 0.4 | | 11 | {b, d} | 0.3 | | 12 | {d, e} | 0.2 | | 13 | {a, b, e} | 0.1 | | 14 | {a, e} | 0.2 | | 15 | {b, e} | 0.3 | | 16 | {a, b} | 0.5 | | 17 | {a} | 0.7 | | 18 | {b} | 0.7 | | 19 | {e} | 0.5 | | 20 | {d} | 0.4 | | 21 | {c} | 0.4 | Use Case[edit]To see some real example of the use of the Eclat algorithm it will be used some data from the northwind database. The northwind database is freely available for download and represents data from an enterprise. In this example it will be used the table order details from the database. The order details table is used to relate the orders with products (in a n to n relationship). The Eclat algorithm will be used to find frequent patterns from this data to see if there are any products that are bought together. Scenario[edit]Given the data from the order details table from the northwind database, find all the frequent itemsets with support = 0.1 and length of at least 2. Input Data[edit]The order details table has the fields: - ID
- primary key
- Order ID
- foreign key from table Orders
- Product ID
- foreign key from table Products
- Quantity
- the quantity bought
- Discount
- the discount offered
- Unit Price
- the unit price of the product
To use the data, some pre-processing is necessary. The table may have many rows that belongs to the same order, so the table was converted in a way that all the rows for one order became only one row in the new table containing the product id's of the products belonging to that order. The fields ID, order id, quantity, discount and unit price was discarded. The data was saved in a txt file called northwind-orders.txt. The file was scripted in a way ready to be loaded as a list object in R. Implementation[edit]To run the example the package arules need to be loaded in R. First, the data is loaded in a list object in R ## 1041 transactions is loaded, the listing below was shortened## some duplicates transactions was introduced to produce some results for the algorithmdata = list( c("2","3","4","6","7","8","10","12","13","14","16","20","23","32","39","41","46","52","55","60","64","66","73","75","77"), c("11","42","72"), c("14","51"), c("41","51","65"), c("22","57","65"), ...)Second, the eclat algorithm is used. itemsets <- eclat(data, parameter = list(support = 0.1, minlen=2, tidLists = TRUE, target="frequent itemsets")) parameter specification: tidLists support minlen maxlen target ext TRUE 0.1 2 5 frequent itemsets FALSEalgorithmic control: sparse sort verbose 7 -2 TRUEeclat - find frequent item sets with the eclat algorithmversion 2.6 (2004.08.16) (c) 2002-2004 Christian Borgeltcreate itemset ... set transactions ...[78 item(s), 1041 transaction(s)] done [0.00s].sorting and recoding items ... [3 item(s)] done [0.00s].creating bit matrix ... [3 row(s), 1041 column(s)] done [0.00s].writing ... [4 set(s)] done [0.00s].Creating S4 object ... done [0.00s]. Output Data[edit]The itemsets object holds the output of the execution of the eclat algorithm. As can be seen above, 4 sets was generated. To see the results it can be used: items support1 {11, 42, 72} 0.19404422 {42, 72} 0.19404423 {11, 42} 0.19404424 {11, 72} 0.1959654 Analysis[edit]As can be seen above, there are 4 frequent itemsets as result of the eclat algorithm. This output was induced by the replication of the transaction {11, 42, 72} many times in the data. This result shows that the tuples {11,42,72},{42,72} and {11,42} has a support of 19,40%; and the tuple {11,72} has a support of 19,60%. The product id's 11, 42 and 72 represents the products Queso Cabrales, Singaporean Hokkien Fried Mee and Mozzarella di Giovanni, respectively. So, the output of the eclat algorithm suggests a strong frequent shop pattern of buying this items together. References[edit] - Hahsler, M.; Buchta, C.; Gruen, B. & Hornik, K. arules: Mining Association Rules and Frequent Itemsets. 2009.
- Hahsler, M.; Gruen, B. & Hornik, K. arules -- A Computational Environment for Mining Association Rules and Frequent Item Sets. Journal of Statistical Software, 2005, 14, 1-25
- Zaki, M. J.;Meira Jr., W. Fundamentals of Data Mining Algorithms. Cambridge University Press, 2009
- Mohammed J. Zaki, Srinivasan Parthasarathy, Mitsunori Ogihara, and Wei Li. New algorithms for fast discovery of association rules. Technical Report 651, Computer Science Department, University of Rochester, Rochester, NY 14627. 1997.
- Christian Borgelt (2003) Efficient Implementations of Apriori and Eclat. Workshop of Frequent Item Set Mining Implementations (FIMI 2003, Melbourne, FL, USA).
|
|
|