IBISWorkbench Node Merging Experiments
Author: Jack Park
Latest edit: 20110417
Background
We shift our research with IBISWorkbench from acting as a reminder agent, returning to its root concept, that of detecting sameness among nodes in hypermedia discourse structures. Discourse structures are, first, those created in IBIS conversations from, e.g. Compendium. Eventually, the platform might generalize to accept and analyze nodes imported from other platforms such as Cohere.
A node is a component of a graph structure as illustrated Figure 1.
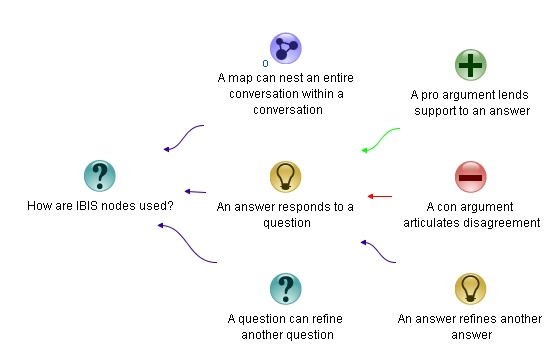
Figure 1: Nodes in an IBIS Conversation
Our general research question is this:
Is it possible to detect two nodes from the same or from different contexts (e.g. different conversations) that say the same thing?
As an example, consider these three statements made in different IBIS nodes:
· Cows and other ruminants release 37% of worlds methane
· Livestock contributes at least 50% of human caused greenhouse gasses
· Livestock contributes 32 6 bn tons of CO2 equivalent
Looked at absent any context, they each say something that appears to be different. Placed into a specific context of answering a question, we have an opportunity to analyze them in a different light. The question is this:
· What are the causes of climate change?
The question sets the context to that of causality. That context is used in an analysis of nodes in conversations, where we seek to identify those nodes that assert causality in any form and strength. When we collect causal statements, we then compare them for sameness.
The definition of sameness is an open topic. We have choices, among them, these:
· Precise sameness in the form of statements that, when compared as raw text, are the same
· Less precise sameness, essentially, saying the same thing even if worded differently
In the second option, we are left with a circular "saying the same thing". What it means to "say the same thing" is a topic for empirical trials, plus philosophical considerations.
In the remaining sections of this report, we describe a software platform that is evolving a solution to our overriding question, and doing so without resort to natural language processing or linguistic analysis. Instead, we rely on decisions made during ontological engineering (defining a universe of discourse and names for things) coupled with simple algorithms and heuristic choices. A goal of this research is to establish a baseline approach to analysis of hypermedia discourse that, over time and further research, can more fully answer our general question.
Philosophical Considerations
We introduce the notion of ontology into this research in a quest to answer the question about what it means to "say the same thing". We introduce a taxonomy of concepts as a means to simplify ontological descriptions of named entities. Overall, as we shall see, merge decisions rely on two aspects of analyzed IBIS statements:
· Same statement type (causal, for now)
· Same actors within each statement
Consider the concepts observed in the three statements above:
· Cows
· ruminants
· Livestock
· methane
· CO2
· greenhouse gasses
In that, we see two general taxonomic trees based on two overriding classes:
· gaseous materials
· animals
How one defines those two taxonomies will make an enormous difference on the outcomes of any study of structured conversations (or any conversation, for that matter). Defining any taxonomy is the process of making ontological commitments, roughly the equivalent of assumptions underlying any experimental procedure. Below, under Experimental Procedure, we will make the ontological commitments .
Risks associated with ontological commitments include the possibility of false positive results. An example of occurs when an animal is included in a taxonomy that is used, say, to identify animals capable of emitting greenhouse gasses.
Pattern Recognition
Comparing statements made in nodes is a pattern recognition process. In our case, it is a process of comparing text messages. We break the process down into two categories, for now, mostly centered on causal statements:
· Determining statement types, e.g. causal, where we must isolate the nature of the statement:
o cause
o not cause
· Determining the actors in the statement, e.g. A cause B
Experimental Procedure
In this section, we define in as precise terms as possible the ontological commitments made in this research, and we specify the processes used for pattern recognition.
Ontological Commitments
Our ontological commitments create a particular basis for comparison. Specifically, we entail an isA hierarchy (taxonomy) that looks like this:
· greenhouse gas
o CO2
o methane
We then create a collection of names for things that reflects that taxonomy. That is, we analyze many statements and isolate as many different ways we can find that people use to name those concepts. Our list of names is then created using the '|' character as a separator, and it looks like this:
greenhouse gas | Greenhouse gas | Greenhouse Gas | greenhouse gasses | Greenhouse gasses | CO2 | co2 | carbon dioxide | Carbon dioxide | Carbon Dioxide | Methane | methane
The first name in that list is taken as the canonical name for that entity. What this means is that, in our analysis, all of those different ways to talk about those named gasses (there are others that belong to that list, but they don't yet exist in our tests) reduce to greenhouse gas.
The taxonomy for animals is this:
· livestock
o ruminant
o cow
The corresponding name list looks like this:
Livestock | Cow | Cows | cow | cows | ruminants | ruminant | livestock
Additionally, we identify a collection of ways in which people assert causality. We call that collection: predicate probes. A small slice of those ways are these:
· is a cause of
· partly causes
· can be linked with
· impacts
· release
Some of those are strong causal statements, others are weak. Some of those phrases are used in different contexts that result in the false positive issue; identification of a statement as causal when it is not causal.
Pattern Matching
We practice a total of three kinds of pattern matching:
· Predicate probes
· Name probes
· TF-IDF scanning
Predicate Probes
We define pattern matching as we practice it by way of an example. Consider this sentence:
· Cows and other ruminants release 37% of worlds methane
Our predicate probe release is detected in that sentence; this sentence is thus identified as a causal assertion. The pattern matching system then returns a list of three elements based on the results of the probe:
[ left side, predicate, right side ]
For example, the sentence above returns this structure after a predicate probe:
["Cows and other ruminants", "cause", "37% of worlds methane" ]
The result is that we have normalized the sentence to the predicate: cause.
We now illustrate a different causal probe, one in which the actors are reversed. The sentence above reduces to the form:
A cause B
The other form is this:
A is caused by B
We wish to normalize all statements to the form A cause B. To do that, we need predicate probes that recognize "is caused by" and transform the results of A is caused by B to B cause A. Our code does that.
Name Probes
We implemented the name taxonomies described above. We apply probes similar to predicate probes against both the left side and the right side of the list returned from the predicate probe. Running name probes against:
[Cows and other ruminants, cause, 37% of worlds methane ]
returns this revised list:
[Livestock, cause, greenhouse gas]
TF-IDF scanning
TF-IDF scanning is a heuristic way of assembling a list of nodes that need further comparison.
<TODO, not yet tested in this context>
Test Data
Our test data consists of a collection of four IBIS conversations related to climate change. They are:
· Anthropogenic Climate Change harvested from Debategraph
· MIT Conversation 1
· MIT Conversation 2
· ScienceSkeptic arguments related to climate change harvested from the Web
That collection results in a total of 1619 nodes, some of which are ignored for reasons of being node types not under consideration. Specific node types ignored are note, reference, decision, and argument. Nodes specifically under consideration are issue, position, pro, and con. As we shall see, in all of those nodes, there are very few causal statements.
Algorithm
The overall IBISWorkbench algorithm is this:
On boot, import a collection of IBIS documents (Compendium XML files)
For each document
Import the XML file and convert it to a Java object that captures the tree structure of the conversation
Flatten the tree to capture individual nodes of the chosen (not ignored) type
For each node thus captured
Analyze the node's label for causal statement
IF label is a causal statement
THEN store the resulting triple structure in the node for later reference
For all nodes collected
In a combinatorial, pairwise, fashion, determine TF-IDF comparisons between nodes
For each pair
If the TF-IDF value is above a given threshold, record in each node the identifier of the compared node for later reflection
For each node (not implemented yet)
IF the node has a TF-IDF-defined mate
THEN study the triples for merge decisions
Results
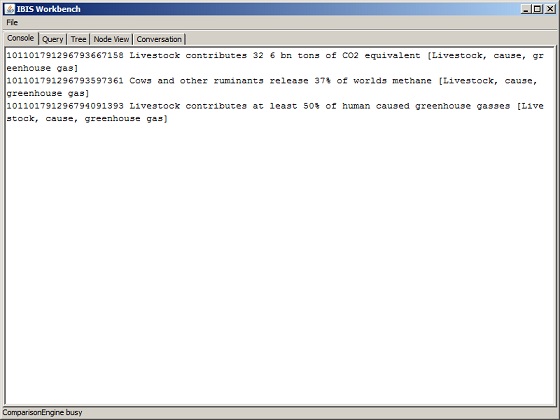
Figure 2: IBISWorkbench Merge Suggestions
Given the present collection of causal probes, IBISWorkbench has identified three, and only three nodes in the entire collection that are causal. As is evident from Figure 2, they all normalize to the very same triple structure [Livestock, cause, greenhouse gas]. They are thus considered candidates for merge operations.
Going forward, we will need to work with data sources that include far more causal claims.
Future Work
We have options for IBISWorkbench. Options include (but are not limited to)
· Simple merge detection among multiple conversations which are intended to be merged into a single conversation
o This merge is structure preserving. The resulting conversation first relies on their mergeability, meaning, they are each in the same context, meaning they each pose either a mergeable statement as the root node, or the questions asked in each are mergeable. From there, the trees grow as the individual conversations grow; if any two sub-tree roots merge, then the child nodes of those sub-tree roots, after merging, must also be tested for merging when combined.
· Construction of a de novo conversation from among any number of conversations
o This merge is not necessarily structure preserving. Necessarily, it would be a knowledge-driven exercise in the fabrication of a conversation tree by selecting and rearranging elements from the source trees. For instance, if one node somewhere in one tree asserts A cause B, and another node elsewhere in another tree asserts A not cause B, then we are faced with editorial choices on ways with which to combine both assertions. One approach, for instance, is to allow the first causal claim to answer its question, then convert the second to a con node which challenges the causal claim.
· Generalize the platform to perform the same analyses on nodes that are not necessarily connected by the same coherence relations as found in IBIS trees. Cohere's graphs are a likely target for this exercise.
o This generalization opens the door to combining IBIS and other graphs into uniform, possibly coherent stories.
Additionally, IBISWorkbench is a largely heuristic platform. The platform is designed and constructed as an agent based system which allows for the addition of agents that extend or change approaches already taken. Over time, we expect that other approaches to subject identification can be added to the workbench. For instance, IBM's Watson has demonstrated the ability to read large quantities of textual material from the web and reduce it to knowledge structures capable of answering questions. Watson employs varieties of NLP and linguistic approaches that are now becoming, at once, well documented, and open source; IBISWorkbench could be extended to include those features.
At present, IBISWorkbench relies on a pre-constructed knowledge base. That knowledgebase is extensible since it is captured in simple text files that IBISWorkbench imports when it is booted. Extending the knowledgebase is a simple matter of adding lines of text to appropriate files. In the future, IBISWorkbench can be extended to make use of other features available in the discourse available to it. For instance, Compendium and Cohere both allow tags to decorate individual nodes. If, as a discipline, those tags were the names of topics referenced in the node, then the workbench has another source of names for things. For tags to work as our taxonomy does, they would need to be entered into, or make reference to a taxonomy that allows for derivation of compatible canonical names.
References