The Randomized weighted majority algorithm is an algorithm that belongs to the machine learning theory. It minimize the mistake-bound of the weighted majority algorithm. For example, each day we get a prediction from some number of experts about whether the stock market is up or down.Then we use them to make our prediction. Our goal is to do nearly as well as best of the experts in hindsight.
Motivation[edit]
In machine learning, the weighted majority algorithm(WMA) is a meta-learning algorithm which "predicts from expert advice".
The algorithm:
initialize all experts to weight 1.for each round: poll all the experts and predict based on a weighted majority vote of their predictions. cut in half the weights of all experts that make a mistake.
Suppose there are n experts and the best experts made m mistakes. the weighted majority algorithm makes at most 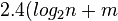 ) mistakes.
) mistakes.
Randomized weighted majority(RWMN)[edit]
) not so good if the best expert makes a mistake 20% of the time. can we do better? yes. we'd like to improve dependence on  . Instead of predicting based on majority vote, we use the weighted as probabilities -Randomized weighted majority. If
. Instead of predicting based on majority vote, we use the weighted as probabilities -Randomized weighted majority. If 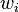 is the weight of expert
is the weight of expert 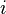 ,
, 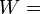
 , then we will follow expert with probability
, then we will follow expert with probability  . Our goal is to bound the worst-case expected number of mistakes, assuming that the adversary(the world) has to select one of the answers as correct before we make our coin toss. Why is this better in the worst case? Idea: worst case for determinisric algorithm(weighted majority algorithm) was when weights split 50/50.But, now it is not so bad since we also have 50/50 chance of getting it right. Also, to trade-off between dependence on and
. Our goal is to bound the worst-case expected number of mistakes, assuming that the adversary(the world) has to select one of the answers as correct before we make our coin toss. Why is this better in the worst case? Idea: worst case for determinisric algorithm(weighted majority algorithm) was when weights split 50/50.But, now it is not so bad since we also have 50/50 chance of getting it right. Also, to trade-off between dependence on and  , we will generalize to multiply by
, we will generalize to multiply by  , instead of necessarily
, instead of necessarily  .
.
Analysis[edit]
At the 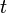 -th round, define
-th round, define  to be the fraction of weight on the wrong answers. so, is the probability we make a mistake on the -th round. Let
to be the fraction of weight on the wrong answers. so, is the probability we make a mistake on the -th round. Let 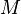 denote the total number of mistakes we made so far. Furthermore, we define
denote the total number of mistakes we made so far. Furthermore, we define ![E[M]=\ \sum_tF_t](http://upload.wikimedia.org/math/1/9/f/19f3a350ad29cc310888f11d90b6c1b3.png) , using the fact that expectation is additive. On the -th round,
, using the fact that expectation is additive. On the -th round,  becomes
becomes 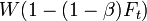 . Reason: on fraction, we are multiplying by
. Reason: on fraction, we are multiplying by 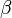 . So,
. So, 
Let's say that is the number of mistakes of the best expert so far. We can use the inequality 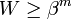 . Now we solve. First, take the natural log of both sides. We get:
. Now we solve. First, take the natural log of both sides. We get: 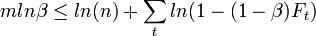 , Simplify:
, Simplify:
 , So,
, So,
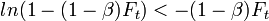 .
.

Now, use ![\ E[M] =\ \sum_tF_t](http://upload.wikimedia.org/math/e/f/0/ef03afc1c04e89737e3a1ed3b391df3b.png) , and the result is:
, and the result is:
![\ E[M] \leq \frac {mln(1/\beta)+ln(n)}{1-\beta}](http://upload.wikimedia.org/math/9/d/c/9dc881a7d39f15e42b49f35d4af0ca4a.png)
Let's see if we made any progress:
If 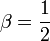 , we get,
, we get,  ,
,
if 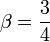 , we get,
, we get,  .
.
so we can see we made progress. Roughly, of the form  .
.
Uses of Randomized weighted Majority(RWMN)[edit]
Can use to combine multiple algorithms to do nearly as well as best in hindsight.
can apply Randomized weighted majority algorithm in situations where experts are making choices that cannot be combined (or can't be combined easily).For instance, repeated game-playing or online shortest path problem.In the online shortest path problem, each expert is telling you a different way to drive to work. You pick one using Randomized weighted majority algorithm. Later you find out how well you would have done, and penalize appropriately. To do this right, we want to generalize from just "losS" of 0 to 1 to losses in [0,1]. Goal of having expected loss be not too much worse than loss of best expert.We generalize by penalize  , meaning having two examples of loss
, meaning having two examples of loss  gives same weight as one example of loss 1 and one example of loss 0 (Analysis still oes through).
gives same weight as one example of loss 1 and one example of loss 0 (Analysis still oes through).
Extensions[edit]
- "Bandit" problem
- Efficient algorithm for some cases with many experts.
- Sleeping experts/"specialists" setting.
See also[edit]
Further reading[edit]