The forward–backward algorithm is an inference algorithm for hidden Markov models which computes the posterior marginals of all hidden state variables given a sequence of observations/emissions  , i.e. it computes, for all hidden state variables
, i.e. it computes, for all hidden state variables 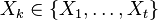 , the distribution
, the distribution  . This inference task is usually called smoothing. The algorithm makes use of the principle of dynamic programming to efficiently compute the values that are required to obtain the posterior marginal distributions in two passes. The first pass goes forward in time while the second goes backward in time; hence the name forward–backward algorithm.
. This inference task is usually called smoothing. The algorithm makes use of the principle of dynamic programming to efficiently compute the values that are required to obtain the posterior marginal distributions in two passes. The first pass goes forward in time while the second goes backward in time; hence the name forward–backward algorithm.
The term forward–backward algorithm is also used to refer to any algorithm belonging to the general class of algorithms that operate on sequence models in a forward–backward manner. In this sense, the descriptions in the remainder of this article refer but to one specific instance of this class.
Contents
[hide] - 1 Overview
- 2 Forward probabilities
- 3 Backward probabilities
- 4 Example
- 5 Performance
- 6 Pseudocode
- 7 Python example
- 8 See also
- 9 References
- 10 External links
Overview[edit]
In the first pass, the forward–backward algorithm computes a set of forward probabilities which provide, for all 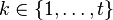 , the probability of ending up in any particular state given the first
, the probability of ending up in any particular state given the first  observations in the sequence, i.e.
observations in the sequence, i.e. 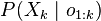 . In the second pass, the algorithm computes a set of backward probabilities which provide the probability of observing the remaining observations given any starting point , i.e.
. In the second pass, the algorithm computes a set of backward probabilities which provide the probability of observing the remaining observations given any starting point , i.e.  . These two sets of probability distributions can then be combined to obtain the distribution over states at any specific point in time given the entire observation sequence:
. These two sets of probability distributions can then be combined to obtain the distribution over states at any specific point in time given the entire observation sequence:

The last step follows from an application of Bayes' rule and the conditional independence of 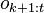 and
and 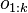 given
given  .
.
As outlined above, the algorithm involves three steps:
- computing forward probabilities
- computing backward probabilities
- computing smoothed values.
The forward and backward steps may also be called "forward message pass" and "backward message pass" - these terms are due to the message-passing used in general belief propagation approaches. At each single observation in the sequence, probabilities to be used for calculations at the next observation are computed. The smoothing step can be calculated simultaneously during the backward pass. This step allows the algorithm to take into account any past observations of output for computing more accurate results.
The forward–backward algorithm can be used to find the most likely state for any point in time. It cannot, however, be used to find the most likely sequence of states (see Viterbi algorithm).
Forward probabilities[edit]
The following description will use matrices of probability values rather than probability distributions, although in general the forward-backward algorithm can be applied to continuous as well as discrete probability models.
We transform the probability distributions related to a given hidden Markov model into matrix notation as follows. The transition probabilities  of a given random variable
of a given random variable 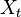 representing all possible states in the hidden Markov model will be represented by the matrix
representing all possible states in the hidden Markov model will be represented by the matrix 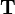 where the row index, i, will represent the start state and the column index, j, represents the target state. The example below represents a system where the probability of staying in the same state after each step is 70% and the probability of transitioning to the other state is 30%. The transition matrix is then:
where the row index, i, will represent the start state and the column index, j, represents the target state. The example below represents a system where the probability of staying in the same state after each step is 70% and the probability of transitioning to the other state is 30%. The transition matrix is then:
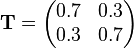
In a typical Markov model we would multiply a state vector by this matrix to obtain the probabilities for the subsequent state. In a hidden Markov model the state is unknown, and we instead observe events associated with the possible states. An event matrix of the form:

provides the probabilities for observing events given a particular state. In the above example, event 1 will be observed 90% of the time if we are in state 1 while event 2 has a 10% probability of occurring in this state. In contrast, event 1 will only be observed 20% of the time if we are in state 2 and event 2 has an 80% chance of occurring. Given a state vector ( ), the probability of observing event j is then:
), the probability of observing event j is then:

This can be represented in matrix form by multiplying the state vector () by an observation matrix (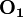 ) containing only diagonal entries. Each entry is the probability of the observed event given each state. Continuing the above example, an observation of event 1 would be:
) containing only diagonal entries. Each entry is the probability of the observed event given each state. Continuing the above example, an observation of event 1 would be:

This allows us to calculate the probabilities associated with transitioning to a new state and observing the given event as:

The probability vector that results contains entries indicating the probability of transitioning to each state and observing the given event. This process can be carried forward with additional observations using:
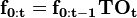
This value is the forward probability vector. The i'th entry of this vector provides:

Typically, we will normalize the probability vector at each step so that its entries sum to 1. A scaling factor is thus introduced at each step such that:
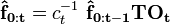
where  represents the scaled vector from the previous step and
represents the scaled vector from the previous step and 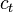 represents the scaling factor that causes the resulting vector's entries to sum to 1. The product of the scaling factors is the total probability for observing the given events irrespective of the final states:
represents the scaling factor that causes the resulting vector's entries to sum to 1. The product of the scaling factors is the total probability for observing the given events irrespective of the final states:

This allows us to interpret the scaled probability vector as:
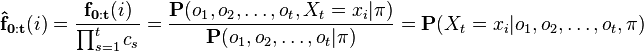
We thus find that the product of the scaling factors provides us with the total probability for observing the given sequence up to time t and that the scaled probability vector provides us with the probability of being in each state at this time.
Backward probabilities[edit]
A similar procedure can be constructed to find backward probabilities. These intend to provide the probabilities:

That is, we now want to assume that we start in a particular state (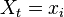 ), and we are now interested in the probability of observing all future events from this state. Since the initial state is assumed as given (i.e. the prior probability of this state = 100%), we begin with:
), and we are now interested in the probability of observing all future events from this state. Since the initial state is assumed as given (i.e. the prior probability of this state = 100%), we begin with:
![\mathbf{b_{T:T}} = [1\ 1\ 1\ \dots]^T](http://upload.wikimedia.org/math/9/3/6/936a935502886c5ff4e56fec69051e3f.png)
Notice that we are now using a column vector while the forward probabilities used row vectors. We can then work backwards using:

While we could normalize this vector as well so that its entries sum to one, this is not usually done. Noting that each entry contains the probability of the future event sequence given a particular initial state, normalizing this vector would be equivalent to applying Bayes' theorem to find the likelihood of each initial state given the future events (assuming uniform priors for the final state vector). However, it is more common to scale this vector using the same constants used in the forward probability calculations.  is not scaled, but subsequent operations use:
is not scaled, but subsequent operations use:
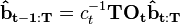
where 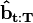 represents the previous, scaled vector. This result is that the scaled probability vector is related to the backward probabilities by:
represents the previous, scaled vector. This result is that the scaled probability vector is related to the backward probabilities by:
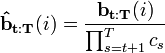
This is useful because it allows us to find the total probability of being in each state at a given time, t, by multiplying these values:

To understand this, we note that  provides the probability for observing the given events in a way that passes through state
provides the probability for observing the given events in a way that passes through state  at time t. This probability includes the forward probabilities covering all events up to time t as well as the backward probabilities which include all future events. This is the numerator we are looking for in our equation, and we divide by the total probability of the observation sequence to normalize this value and extract only the probability that . These values are sometimes called the "smoothed values" as they combine the forward and backward probabilities to compute a final probability.
at time t. This probability includes the forward probabilities covering all events up to time t as well as the backward probabilities which include all future events. This is the numerator we are looking for in our equation, and we divide by the total probability of the observation sequence to normalize this value and extract only the probability that . These values are sometimes called the "smoothed values" as they combine the forward and backward probabilities to compute a final probability.
The values 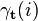 thus provide the probability of being in each state at time t. As such, they are useful for determining the most probable state at any time. It should be noted, however, that the term "most probable state" is somewhat ambiguous. While the most probable state is the most likely to be correct at a given point, the sequence of individually probable states is not likely to be the most probable sequence. This is because the probabilities for each point are calculated independently of each other. They do not take into account the transition probabilities between states, and it is thus possible to get states at two moments (t and t+1) that are both most probable at those time points but which have very little probability of occurring together, i.e.
thus provide the probability of being in each state at time t. As such, they are useful for determining the most probable state at any time. It should be noted, however, that the term "most probable state" is somewhat ambiguous. While the most probable state is the most likely to be correct at a given point, the sequence of individually probable states is not likely to be the most probable sequence. This is because the probabilities for each point are calculated independently of each other. They do not take into account the transition probabilities between states, and it is thus possible to get states at two moments (t and t+1) that are both most probable at those time points but which have very little probability of occurring together, i.e. 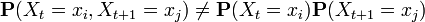 . The most probable sequence of states that produced an observation sequence can be found using the Viterbi algorithm.
. The most probable sequence of states that produced an observation sequence can be found using the Viterbi algorithm.
Example[edit]
This example takes as its basis the umbrella world in Russell & Norvig 2010 Chapter 15 pp. 566 in which we would like to infer the weather given observation of a man either carrying or not carrying an umbrella. We assume two possible states for the weather: state 1 = rain, state 2 = no rain. We assume that the weather has a 70% chance of staying the same each day and a 30% chance of changing. The transition probabilities are then:
We also assume each state generates 2 events: event 1 = umbrella, event 2 = no umbrella. The conditional probabilities for these occurring in each state are given by the probability matrix:
We then observe the following sequence of events: {umbrella, umbrella, no umbrella, umbrella, umbrella} which we will represent in our calculations as:

Note that  differs from the others because of the "no umbrella" observation.
differs from the others because of the "no umbrella" observation.
In computing the forward probabilities we begin with:
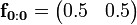
which is our prior state vector indicating that we don't know which state the weather is in before our observations. While a state vector should be given as a row vector, we will use the transpose of the matrix so that the calculations below are easier to read. Our calculations are then written in the form:
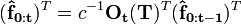
instead of:

Notice that the transformation matrix is also transposed, but in our example the transpose is equal to the original matrix. Performing these calculations and normalizing the results provides:

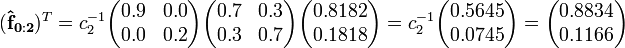


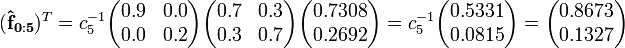
For the backward probabilities we start with:

We are then able to compute (using the observations in reverse order and normalizing with different constants):
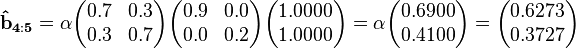

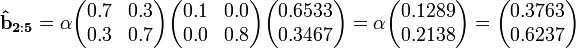

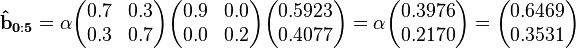
Finally, we will compute the smoothed probability values. These result also must be scaled so that its entries sum to 1 because we did not scale the backward probabilities with the 's found earlier. The backward probability vectors above thus actually represent the likelihood of each state at time t given the future observations. Because these vectors are proportional to the actual backward probabilities, the result has to be scaled an additional time.
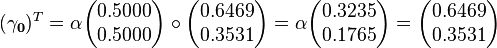


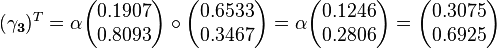
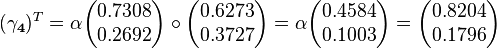

Notice that the value of  is equal to
is equal to  and that
and that  is equal to
is equal to  . This follows naturally because both and begin with uniform priors over the initial and final state vectors (respectively) and take into account all of the observations. However, will only be equal to when our initial state vector represents a uniform prior (i.e. all entries are equal). When this is not the case needs to be combined with the initial state vector to find the most likely initial state. We thus find that the forward probabilities by themselves are sufficient to calculate the most likely final state. Similarly, the backward probabilities can be combined with the initial state vector to provide the most probable initial state given the observations. The forward and backward probabilities need only be combined to infer the most probable states between the initial and final points.
. This follows naturally because both and begin with uniform priors over the initial and final state vectors (respectively) and take into account all of the observations. However, will only be equal to when our initial state vector represents a uniform prior (i.e. all entries are equal). When this is not the case needs to be combined with the initial state vector to find the most likely initial state. We thus find that the forward probabilities by themselves are sufficient to calculate the most likely final state. Similarly, the backward probabilities can be combined with the initial state vector to provide the most probable initial state given the observations. The forward and backward probabilities need only be combined to infer the most probable states between the initial and final points.
The calculations above reveal that the most probable weather state on every day except for the third one was "rain." They tell us more than this, however, as they now provide a way to quantify the probabilities of each state at different times. Perhaps most importantly, our value at quantifies our knowledge of the state vector at the end of the observation sequence. We can then use this to predict the probability of the various weather states tomorrow as well as the probability of observing an umbrella.
Performance[edit]
The brute-force procedure for the solution of this problem is the generation of all possible  state sequences and calculating the joint probability of each state sequence with the observed series of events. This approach has time complexity
state sequences and calculating the joint probability of each state sequence with the observed series of events. This approach has time complexity  , where
, where  is the length of sequences and
is the length of sequences and  is the number of symbols in the state alphabet. This is intractable for realistic problems, as the number of possible hidden node sequences typically is extremely high. However, the forward–backward algorithm has time complexity
is the number of symbols in the state alphabet. This is intractable for realistic problems, as the number of possible hidden node sequences typically is extremely high. However, the forward–backward algorithm has time complexity 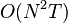 .
.
An enhancement to the general forward-backward algorithm, called the Island algorithm, trades smaller memory usage for longer running time, taking  time and
time and  memory. On a computer with an unlimited number of processors, this can be reduced to total time, while still taking only memory.[1]
memory. On a computer with an unlimited number of processors, this can be reduced to total time, while still taking only memory.[1]
In addition, algorithms have been developed to compute  efficiently through online smoothing such as the fixed-lag smoothing (FLS) algorithm Russell & Norvig 2010 Figure 15.6 pp. 580.
efficiently through online smoothing such as the fixed-lag smoothing (FLS) algorithm Russell & Norvig 2010 Figure 15.6 pp. 580.
Pseudocode[edit]
ForwardBackward(guessState, sequenceIndex): if sequenceIndex is past the end of the sequence, return 1 if (guessState, sequenceIndex) has been seen before, return saved result result = 0 for each neighboring state n: result = result + (transition probability from guessState to n given observation element at sequenceIndex) * ForwardBackward(n, sequenceIndex+1) save result for (guessState, sequenceIndex) return result
Python example[edit]
Given HMM (just like in Viterbi algorithm) represented in the Python programming language:
states = ('Healthy', 'Fever')end_state = 'E' observations = ('normal', 'cold', 'dizzy') start_probability = {'Healthy': 0.6, 'Fever': 0.4} transition_probability = { 'Healthy' : {'Healthy': 0.69, 'Fever': 0.3, 'E': 0.01}, 'Fever' : {'Healthy': 0.4, 'Fever': 0.59, 'E': 0.01}, } emission_probability = { 'Healthy' : {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1}, 'Fever' : {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6}, }We can write implementation like this:
def fwd_bkw(x, states, a_0, a, e, end_st): L = len(x) fwd = [] f_prev = {} # forward part of the algorithm for i, x_i in enumerate(x): f_curr = {} for st in states: if i == 0: # base case for the forward part prev_f_sum = a_0[st] else: prev_f_sum = sum(f_prev[k]*a[k][st] for k in states) f_curr[st] = e[st][x_i] * prev_f_sum fwd.append(f_curr) f_prev = f_curr p_fwd = sum(f_curr[k]*a[k][end_st] for k in states) bkw = [] b_prev = {} # backward part of the algorithm for i, x_i_plus in enumerate(reversed(x[1:]+(None,))): b_curr = {} for st in states: if i == 0: # base case for backward part b_curr[st] = a[st][end_st] else: b_curr[st] = sum(a[st][l]*e[l][x_i_plus]*b_prev[l] for l in states) bkw.insert(0,b_curr) b_prev = b_curr p_bkw = sum(a_0[l] * e[l][x[0]] * b_curr[l] for l in states) # merging the two parts posterior = {} for st in states: posterior[st] = [fwd[i][st]*bkw[i][st]/p_fwd for i in range(L)] assert p_fwd == p_bkw return fwd, bkw, posteriorThe function fwd_bkw takes the following arguments: x is the sequence of observations, e.g. ['normal', 'cold', 'dizzy']; states is the set of hidden states; a_0 is the start probability; a are the transition probabilities; and e are the emission probabilities.
For simplicity of code, we assume that the observation sequence x is non-empty and that a[i][j] and e[i][j] is defined for all states i,j.
In the running example, the forward-backward algorithm is used as follows:
def example(): return fwd_bkw(observations, states, start_probability, transition_probability, emission_probability, end_state) for line in example(): print(' '.join(map(str, line)))See also[edit]
References[edit]
- Jump up^ J. Binder, K. Murphy and S. Russell. Space-Efficient Inference in Dynamic Probabilistic Networks. Int'l, Joint Conf. on Artificial Intelligence, 1997.
- Lawrence R. Rabiner, A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition. Proceedings of the IEEE, 77 (2), p. 257–286, February 1989. 10.1109/5.18626
- Lawrence R. Rabiner, B. H. Juang (January 1986). "An introduction to hidden Markov models". IEEE ASSP Magazine: 4–15.
- Eugene Charniak (1993). Statistical Language Learning. Cambridge, Massachusetts: MIT Press. ISBN 978-0-262-53141-2.
- Stuart Russell and Peter Norvig (2010). Artificial Intelligence A Modern Approach 3rd Edition. Upper Saddle River, New Jersey: Pearson Education/Prentice-Hall. ISBN 978-0-13-604259-4.
External links[edit]