C4.5 is an algorithm used to generate a decision tree developed by Ross Quinlan.[1] C4.5 is an extension of Quinlan's earlier ID3 algorithm. The decision trees generated by C4.5 can be used for classification, and for this reason, C4.5 is often referred to as a statistical classifier.
Algorithm[edit]
C4.5 builds decision trees from a set of training data in the same way as ID3, using the concept of information entropy. The training data is a set 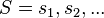 of already classified samples. Each sample
of already classified samples. Each sample  consists of a p-dimensional vector
consists of a p-dimensional vector 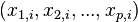 , where the
, where the 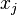 represent attributes or features of the sample, as well as the class in which falls.
represent attributes or features of the sample, as well as the class in which falls.
At each node of the tree, C4.5 chooses the attribute of the data that most effectively splits its set of samples into subsets enriched in one class or the other. The splitting criterion is the normalized information gain (difference in entropy). The attribute with the highest normalized information gain is chosen to make the decision. The C4.5 algorithm then recurses on the smaller sublists.
This algorithm has a few base cases.
- All the samples in the list belong to the same class. When this happens, it simply creates a leaf node for the decision tree saying to choose that class.
- None of the features provide any information gain. In this case, C4.5 creates a decision node higher up the tree using the expected value of the class.
- Instance of previously-unseen class encountered. Again, C4.5 creates a decision node higher up the tree using the expected value.
Pseudocode[edit]
In pseudocode, the general algorithm for building decision trees is:[2]
- Check for base cases
- For each attribute a
- Find the normalized information gain ratio from splitting on a
- Let a_best be the attribute with the highest normalized information gain
- Create a decision node that splits on a_best
- Recurse on the sublists obtained by splitting on a_best, and add those nodes as children of node
Implementations[edit]
J48 is an open source Java implementation of the C4.5 algorithm in the weka data mining tool. TimeSleuth [3] extends C4.5's use to temporal and causal discovery. TimeSleuth also allows converting C4.5 rules to Prolog statements [4]
Improvements from ID3 algorithm[edit]
C4.5 made a number of improvements to ID3. Some of these are:
- Handling both continuous and discrete attributes - In order to handle continuous attributes, C4.5 creates a threshold and then splits the list into those whose attribute value is above the threshold and those that are less than or equal to it.[5]
- Handling training data with missing attribute values - C4.5 allows attribute values to be marked as ? for missing. Missing attribute values are simply not used in gain and entropy calculations.
- Handling attributes with differing costs.
- Pruning trees after creation - C4.5 goes back through the tree once it's been created and attempts to remove branches that do not help by replacing them with leaf nodes.
Improvements in C5.0/See5 algorithm[edit]
Quinlan went on to create C5.0 and See5 (C5.0 for Unix/Linux, See5 for Windows) which he markets commercially. C5.0 offers a number of improvements on C4.5. Some of these are[6][third-party source needed]:
- Speed - C5.0 is significantly faster than C4.5 (several orders of magnitude)
- Memory usage - C5.0 is more memory efficient than C4.5
- Smaller decision trees - C5.0 gets similar results to C4.5 with considerably smaller decision trees.
- Support for boosting - Boosting improves the trees and gives them more accuracy.
- Weighting - C5.0 allows you to weight different cases and misclassification types.
- Winnowing - a C5.0 option automatically winnows the attributes to remove those that may be unhelpful.
Source for a single-threaded Linux version of C5.0 is available under the GPL.
See also[edit]
References[edit]
- Jump up^ Quinlan, J. R. C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers, 1993.
- Jump up^ S.B. Kotsiantis, Supervised Machine Learning: A Review of Classification Techniques, Informatica 31(2007) 249-268, 2007
- Jump up^ K. Karimi and H.J. Hamilton, TimeSleuth: A Tool for Discovering Causal and Temporal Rules, ICTAI, 2002
- Jump up^ K. Karimi and H.J. Hamilton, Logical Decision Rules: Teaching C4.5 to Speak Prolog, IDEAL, 2000
- Jump up^ J. R. Quinlan. Improved use of continuous attributes in c4.5. Journal of Artificial Intelligence Research, 4:77-90, 1996.
- Jump up^ Is See5/C5.0 Better Than C4.5?
External links[edit]