|
![]()
| Growing self-organizing map (GSOM) Component1 #305670 A growing self-organizing map (GSOM) is a growing variant of the popular self-organizing map (SOM). The GSOM was developed to address the issue of identifying a suitable map size in the SOM. It starts with a minimal number of nodes (usually 4) and grows new nodes on the boundary based on a heuristic. By using the value called Spread Factor (SF), the data analyst has the ability to control the growth of the GSOM. | A growing self-organizing map (GSOM) is a growing variant of the popular self-organizing map (SOM). The GSOM was developed to address the issue of identifying a suitable map size in the SOM. It starts with a minimal number of nodes (usually 4) and grows new nodes on the boundary based on a heuristic. By using the value called Spread Factor (SF), the data analyst has the ability to control the growth of the GSOM. All the starting nodes of the GSOM are boundary nodes, i.e. each node has the freedom to grow in its own direction at the beginning. (Fig. 1) New Nodes are grown from the boundary nodes. Once a node is selected for growing all its free neighboring positions will be grown new nodes. The figure shows the three possible node growth options for a rectangular GSOM.  Node growth options in GSOM: (a) one new node, (b) two new nodes and (c) three new nodes. Contents [hide] - 1 The algorithm
- 2 Applications
- 3 References
- 4 Bibliography
- 5 See also
The algorithm[edit]The GSOM process is as follows: - Initialization phase:
- Initialize the weight vectors of the starting nodes (usually four) with random numbers between 0 and 1.
- Calculate the growth threshold (
 ) for the given data set of dimension ) for the given data set of dimension  according to the spread factor ( according to the spread factor (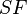 ) using the formula ) using the formula 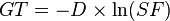 - Growing Phase:
- Present input to the network.
- Determine the weight vector that is closest to the input vector mapped to the current feature map (winner), using Euclidean distance (similar to the SOM). This step can be summarized as: find
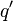 such that such that 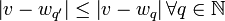 where where  , , 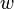 are the input and weight vectors respectively, are the input and weight vectors respectively,  is the position vector for nodes and is the position vector for nodes and  is the set of natural numbers. is the set of natural numbers. - The weight vector adaptation is applied only to the neighborhood of the winner and the winner itself. The neighborhood is a set of neurons around the winner, but in the GSOM the starting neighborhood selected for weight adaptation is smaller compared to the SOM (localized weight adaptation). The amount of adaptation (learning rate) is also reduced exponentially over the iterations. Even within the neighborhood, weights that are closer to the winner are adapted more than those further away. The weight adaptation can be described by
 where the Learning Rate where the Learning Rate  , ,  is a sequence of positive parameters converging to zero as is a sequence of positive parameters converging to zero as  . . 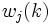 , ,  are the weight vectors of the node are the weight vectors of the node  before and after the adaptation and before and after the adaptation and 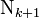 is the neighbourhood of the winning neuron at the is the neighbourhood of the winning neuron at the  th iteration. The decreasing value of in the GSOM depends on the number of nodes existing in the map at time th iteration. The decreasing value of in the GSOM depends on the number of nodes existing in the map at time  . . - Increase the error value of the winner (error value is the difference between the input vector and the weight vectors).
- When
 (where (where  is the total error of node is the total error of node  and is the growth threshold). Grow nodes if i is a boundary node. Distribute weights to neighbors if is a non-boundary node. and is the growth threshold). Grow nodes if i is a boundary node. Distribute weights to neighbors if is a non-boundary node. - Initialize the new node weight vectors to match the neighboring node weights.
- Initialize the learning rate (
 ) to its starting value. ) to its starting value. - Repeat steps 2 – 7 until all inputs have been presented and node growth is reduced to a minimum level.
- Smoothing phase.
- Reduce learning rate and fix a small starting neighborhood.
- Find winner and adapt the weights of the winner and neighbors in the same way as in growing phase.
 Approximation of a spiral with noise by 1D SOM (the upper row) and GSOM (the lower row) with 50 (the first column) and 100 (the second column) nodes. The Fraction of variance unexplained is: a) 4.68% (SOM, 50 nodes); b) 1.69% (SOM, 100 nodes); c) 4.20% (GSOM, 50 nodes); d) 2.32% (GSOM, 100 nodes). The initial approximation for SOM was equidistribution of nodes in a segment on the first principal component with the same variance as for the data set. The initial approximation for GSOM was the mean point. [1]Applications[edit]The GSOM can be used for many preprocessing tasks in Data mining, for Nonlinear dimensionality reduction, for approximation of principal curves and manifolds, for clustering and classification. It gives often the better representation of the data geometry than the SOM (see the classical benchmark for principal curves on the left). References[edit]Bibliography[edit] - Hsu, A., Tang, S. and Halgamuge, S. K. (2003) An unsupervised hierarchical dynamic self-organizing approach to cancer class discovery and marker gene identification in microarray data. Bioinformatics 19(16): pp 2131-2140
- Alahakoon, D., Halgamuge, S. K. and Sirinivasan, B. (2000) Dynamic Self Organizing Maps With Controlled Growth for Knowledge Discovery, IEEE Transactions on Neural Networks, Special Issue on Knowledge Discovery and Data Mining, 11, pp 601-614.
- Alahakoon, D., Halgamuge, S. K. and Sirinivasan, B. (1998) A Structure Adapting Feature Map for Optimal Cluster Representation in Proceedings of The 5th International Conference on Neural Information Processing (ICONIP 98), Kitakyushu, Japan, pp 809-812
- Alahakoon, D., Halgamuge, S. K. and Sirinivasan, B. (1998) A Self Growing Cluster Development Approach to Data Mining in Proceedings of IEEE International Conference on Systems, Man and Cybernetics, San Diego, USA, pp 2901-2906
- Alahakoon, D. and Halgamuge, S. K. (1998) Knowledge Discovery with Supervised and Unsupervised Self Evolving Neural Networks in Proceedings of 5th International Conference on Soft Computing and Information/Intelligent Systems, Fukuoka, Japan, pp 907-910
See also[edit] |
|
|