Single-linkage clustering
Single-linkage clustering is one of several methods of agglomerative hierarchical clustering. In the beginning of the process, each element is in a cluster of its own. The clusters are then sequentially combined into larger clusters, until all elements end up being in the same cluster. At each step, the two clusters separated by the shortest distance are combined.
Single-linkage clustering is one of several methods of agglomerative hierarchical clustering. In the beginning of the process, each element is in a cluster of its own. The clusters are then sequentially combined into larger clusters, until all elements end up being in the same cluster. At each step, the two clusters separated by the shortest distance are combined. The definition of 'shortest distance' is what differentiates between the different agglomerative clustering methods. In single-linkage clustering, the link between two clusters is made by a single element pair, namely those two elements (one in each cluster) that are closest to each other. The shortest of these links that remains at any step causes the fusion of the two clusters whose elements are involved. The method is also known as nearest neighbour clustering. The result of the clustering can be visualized as a dendrogram, which shows the sequence of cluster fusion and the distance at which each fusion took place.[1]
Mathematically, the linkage function – the distance D(X,Y) between clusters X and Y – is described by the expression

where X and Y are any two sets of elements considered as clusters, and d(x,y) denotes the distance between the two elements x and y.
A drawback of this method is the so-called chaining phenomenon, which refers to the gradual growth of a cluster as one element at a time gets added to it. This may lead to impractically heterogeneous clusters and difficulties in defining classes that could usefully subdivide the data.
- 1 Naive Algorithm
- 2 Optimally efficient algorithm
- 3 Other linkages
- 4 External links
- 5 References
Naive Algorithm[edit]
The following algorithm is an agglomerative scheme that erases rows and columns in a proximity matrix as old clusters are merged into new ones. The 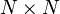 proximity matrix D contains all distances d(i,j). The clusterings are assigned sequence numbers 0,1,......, (n − 1) and L(k) is the level of the kth clustering. A cluster with sequence number m is denoted (m) and the proximity between clusters (r) and (s) is denoted d[(r),(s)].
proximity matrix D contains all distances d(i,j). The clusterings are assigned sequence numbers 0,1,......, (n − 1) and L(k) is the level of the kth clustering. A cluster with sequence number m is denoted (m) and the proximity between clusters (r) and (s) is denoted d[(r),(s)].
The algorithm is composed of the following steps:
- Begin with the disjoint clustering having level L(0) = 0 and sequence number m = 0.
- Find the most similar pair of clusters in the current clustering, say pair (r), (s), according to d[(r),(s)] = min d[(i),(j)] where the minimum is over all pairs of clusters in the current clustering.
- Increment the sequence number: m = m + 1. Merge clusters (r) and (s) into a single cluster to form the next clustering m. Set the level of this clustering to L(m) = d[(r),(s)]
- Update the proximity matrix, D, by deleting the rows and columns corresponding to clusters (r) and (s) and adding a row and column corresponding to the newly formed cluster. The proximity between the new cluster, denoted (r,s) and old cluster (k) is defined as d[(k), (r,s)] = min d[(k),(r)], d[(k),(s)].
- If all objects are in one cluster, stop. Else, go to step 2.
Optimally efficient algorithm[edit]
The algorithm explained above is easy to understand but of complexity 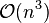 . In 1973, R. Sibson proposed an optimally efficient algorithm of only complexity
. In 1973, R. Sibson proposed an optimally efficient algorithm of only complexity 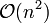 known as SLINK.[2]
known as SLINK.[2]
![[icon]](http://upload.wikimedia.org/wikipedia/commons/thumb/1/1c/Wiki_letter_w_cropped.svg/20px-Wiki_letter_w_cropped.svg.png) | This section requires expansion.(October 2011) |
Other linkages[edit]
This is essentially the same as Kruskal's algorithm for minimum spanning trees. However, in single linkage clustering, the order in which clusters are formed is important, while for minimum spanning trees what matters is the set of pairs of points that form distances chosen by the algorithm.
Alternative linkage schemes include complete linkage and Average linkage clustering - implementing a different linkage in the naive algorithm is simply a matter of using a different formula to calculate inter-cluster distances in the initial computation of the proximity matrix and in step 4 of the above algorithm. An optimally efficient algorithm is however not available for arbitrary linkages. The formula that should be adjusted has been highlighted using bold text.
External links[edit]
References[edit]
- Jump up^ Legendre, P. & Legendre, L. 1998. Numerical Ecology. Second English Edition. 853 pages.
- Jump up^ R. Sibson (1973). "SLINK: an optimally efficient algorithm for the single-link cluster method". The Computer Journal (British Computer Society) 16 (1): 30–34.